R2D3¶
Overview¶
R2D3 (Recurrent Replay Distributed DQN from Demonstrations) was first proposed in the paper Making Efficient Use of Demonstrations to Solve Hard Exploration Problems , it can effectively use expert demonstration trajectories to solve problems with the following 3 properties: initial condition height Variable, partially observable, difficult to explore. In addition they introduce a set of eight tasks that combine these three properties and show that R2D3 can solve tasks like these, notably, some other state-of-the-art methods on tasks like this, with or without experts Demonstration trajectories, even possible after tens of billions of exploration steps Can’t see a successful trajectory. R2D3 is essentially a distributed framework and recurrent neural network structure that effectively combines the R2D2 algorithm, and a loss function specially designed for learning from expert trajectories in DQfD.
Quick Facts¶
1. The baseline reinforcement learning algorithm of R2D3 is R2D2 , you can refer to our implementation R2D2 , It is essentially a DQN algorithm based on a distributed framework, using Double Q Networks, Dueling Architecture, and n-step TD loss.
2. R2D3 utilizes the loss functions of DQfD, including: one-step and n-step temporal difference loss, L2 regularization loss of neural network parameters (optional), supervised large margin classification loss (supervised large margin classification loss). The main difference is that all the Q values in the R2D3 loss function are calculated after the sequence samples are passed through the recurrent neural Q network, while the Q values in the original DQfD are passed through a one-step sample through a convolutional network and/or a forward fully connected network. get.
3. Since R2D3 operates on sequence samples, its expert trajectory should also be given in the form of sequence samples. In the specific implementation, we often use the expert model obtained after the convergence of another baseline reinforcement learning algorithm (such as PPO or R2D2) to To generate the corresponding expert demonstration trajectory, we specially write the corresponding strategy function to generate expert demonstration from such an expert model, See ppo_offpolicy_collect_traj.py and r2d2_collect_traj.py .
When training the Q network, for each sequence sample in the sampled mini-batch, the probability of pho is an expert demonstration sequence sample, and the probability of 1-pho is an empirical sequence sample of the interaction between the agent and the environment.
5. R2D3 is proposed to solve difficult exploration problems in highly variable initial conditions and partially observable environments. For other exploration-related papers, readers can refer to NGU , it is a fusion of ICM and RND and other exploration methods.
Key Equations¶
The overall distributed training process of the R2D3 algorithm is as follows:
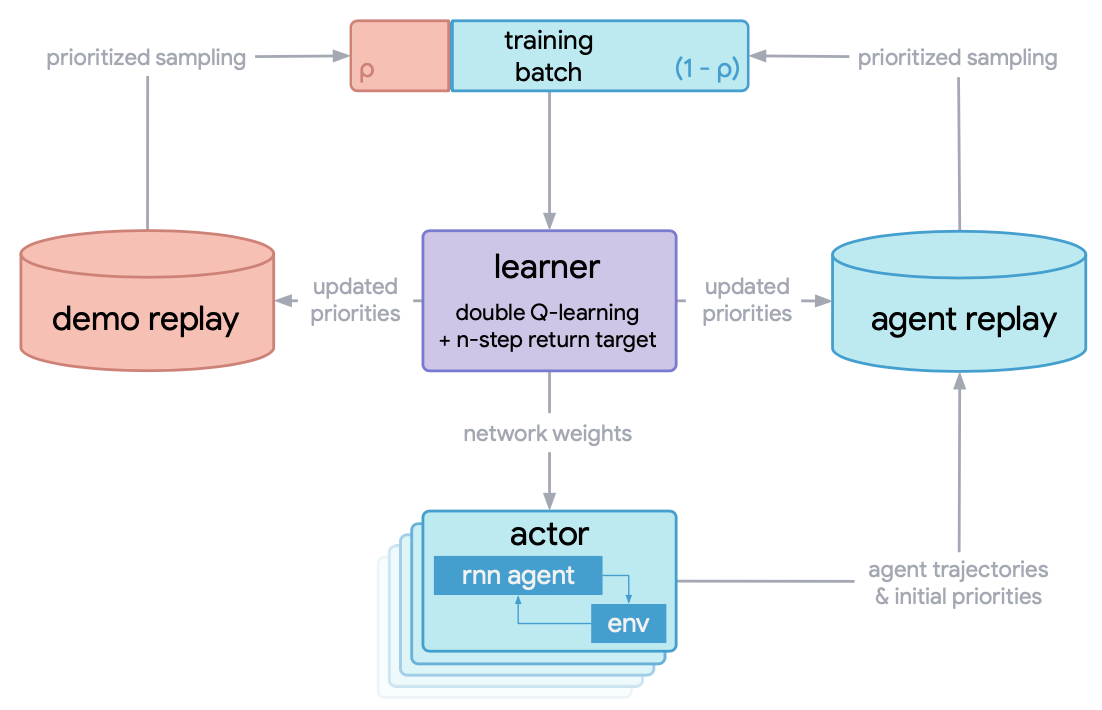
The mini_batch sampled in the learner for training the Q network contains two parts: 1. The expert demonstration trajectory, 2. The experience trajectory generated by the agent interacting with the environment during the training process. The ratio between expert demonstration and agent experience is a critical hyperparameter that must be carefully tuned to achieve good performance.
The Q network structure diagram of the R2D3 algorithm is as follows:
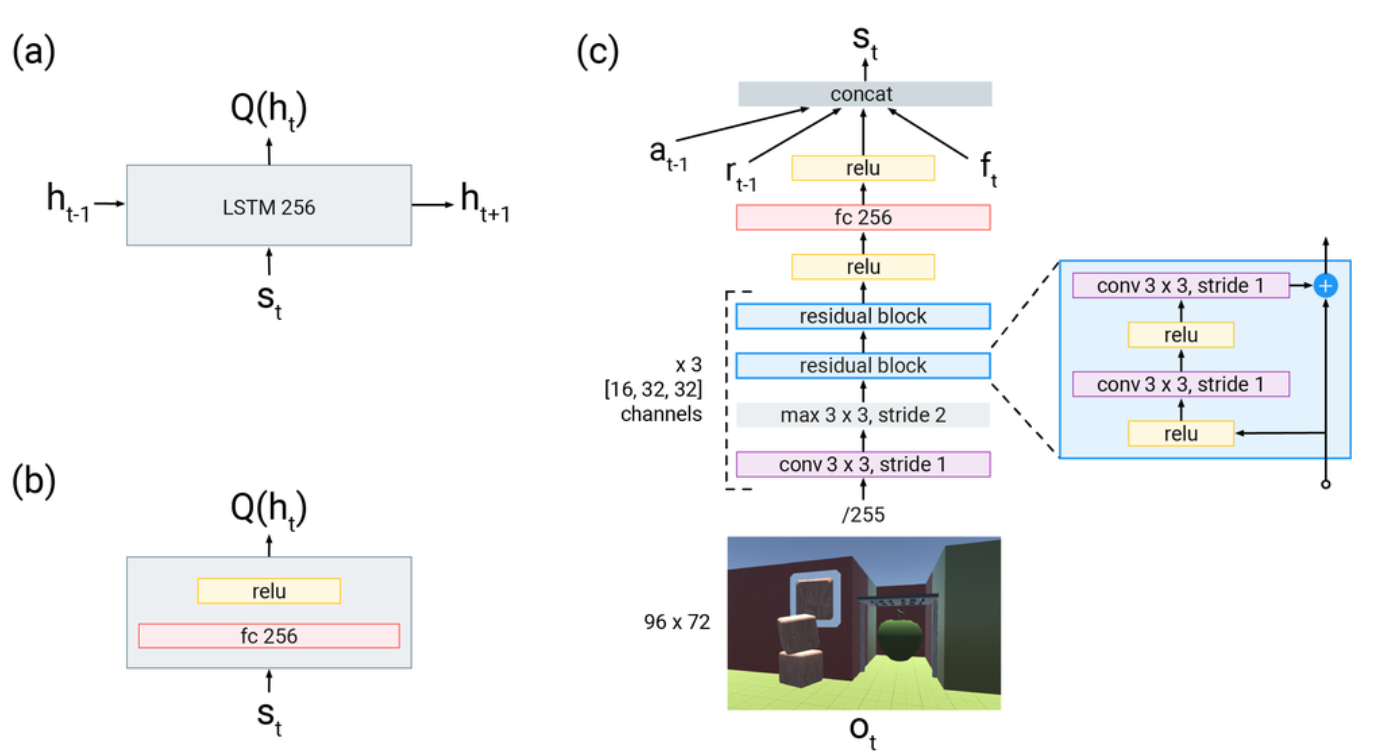
(a) The recurrent head used by the R2D3 agent. (b) The feedforward head used by the DQfD agent. (c) indicates that the input is an image frame of size 96x72, Then pass a ResNet, and then combine the action of the previous moment, the reward of the previous moment and other proprioceptive features of the current moment (proprioceptive features) \(f_{t}\) (including acceleration, whether the avatar is holding the object and the hand Auxiliary information such as relative distance to avatar Concatenate (concat) into a new vector, pass in the head in a) and b), and use it to calculate the Q value.
The loss function setting of r2d3 is described below, which is the same as DQfD, but all Q values here are calculated by the recurrent neural network described above. include: One-step temporal difference loss, n-step temporal difference loss, supervised large interval classification loss, L2 regularization loss for neural network parameters (optional). A temporal difference loss ensures that the network satisfies the Bellman equation, a supervised loss is used to make the expert presenter’s action Q-value at least one interval (a constant value) higher than the Q-value of other actions, and an L2 regularization loss for network weights and biases is used to prevent The Q-network overfits on a relatively small number of expert demo datasets.
In addition to the usual 1-step turn, R2D3 also adds n-step return, which helps to propagate the Q-value of the expert trajectory to all early states for better learning.
The n-step return is:
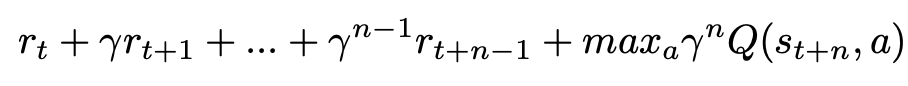
Supervision loss is critical to the performance of training. Due to the following conditions: 1.Expert demonstration data may only cover a small part of the complete state space, 2.The data does not contain, (a specific state, all possible actions) state-action pairs, Therefore many state-action pairs never appear in the expert sample. If we only use the Q-learning loss to update the Q network towards the maximum Q value of the next state, the network will tend to update towards the highest of those inaccurate Q values, And the network will propagate these errors through the Q function throughout the learning process, causing the accumulation of errors to cause overestimation problems. Here the supervised large margin classification loss is adopted to alleviate this problem, Its calculation formula is:
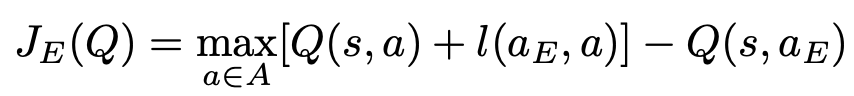
Where \(a_{E}\) represents the action performed by the expert. \(l(a_{E}, a)\) is a marginal function, 0 when \(a = a_{E}\) , and a positive constant otherwise. Minimizing this supervision loss forces the Q-value of actions other than those performed by the expert presenter to be at least one interval lower than the Q-value of the expert presenter’s action. By adding this loss, the Q-values of actions not encountered in the expert data set are changed into values within a reasonable range, and the greedy policy derived from the learned value function is made to mimic the policy of the expert demonstrator.
Our specific implementation in DI-engine is as follows:
l = margin_function * torch.ones_like(q) l.scatter_(1, action.unsqueeze(1).long(), torch.zeros_like(q)) JE = is_expert * (torch.max(q + l.to(device), dim=1)[0] - q_s_a)The overall loss that is ultimately used to update the Q-network is a linear combination of all four of the above losses:
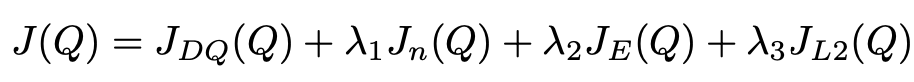
Pseudo-code¶
Below is the pseudocode for the R2D3 agent learner and actor. A single learner process samples data samples from the expert demo buffer and agent experience buffer for computing the loss function, updating its Q network parameters. A parallel actor process interacts with different independent A environment instances to quickly obtain diverse data, and then puts the data into the agent experience buffer. A actor will regularly obtain the latest parameters on the learner.


Important Implementation Details¶
1. The mini-batch used to calculate the loss function is sampled from the expert demonstration buffer and the agent experience buffer. The mini-batch contains <batch_size> sequence samples, sampled from the expert demonstration buffer with the probability of pho, Sample from the agent experience buffer with 1-pho probability. The specific implementation method is as follows. By sampling from the uniform distribution of [0, 1] of size <batch_size>, if the sampling value is greater than pho, an expert demonstration trajectory is selected. The number of sample values greater than pho in the <batch_size> sample values is the number of expert demonstrations in this mini-batch.
2. Since the baseline algorithm R2D2 adopts priority sampling, for a sequence sample, the TD error at each moment is the absolute value of the sum of the 1-step TD error and the n-step TD error, and the TD error is experienced at all times in this sequence. weighted sum of mean and max on
as the priority for the entire sequence of samples. Since the loss functions corresponding to expert data and experience data are different, we set up two independent replay_buffers in R2D2, expert_buffer for expert demonstration , and replay_buffer for agent experience ,
And separate the priority sampling and the update of the relevant parameters in the buffer.
# using the mixture of max and mean absolute n-step TD-errors as the priority of the sequence
td_error_per_sample = 0.9 * torch.max(
torch.stack(td_error), dim=0
)[0] + (1 - 0.9) * (torch.sum(torch.stack(td_error), dim=0) / (len(td_error) + 1e-8))
# td_error shape list(<self._unroll_len_add_burnin_step-self._burnin_step-self._nstep>, B), for example, (75,64)
# torch.sum(torch.stack(td_error), dim=0) can also be replaced with sum(td_error)
...
if learner.policy.get_attribute('priority'):
# When collector, set replay_buffer_idx and replay_unique_id for each data item, priority = 1.\
# When learner, assign priority for each data item according their loss
learner.priority_info_agent = deepcopy(learner.priority_info)
learner.priority_info_expert = deepcopy(learner.priority_info)
learner.priority_info_agent['priority'] = learner.priority_info['priority'][0:agent_batch_size]
learner.priority_info_agent['replay_buffer_idx'] = learner.priority_info['replay_buffer_idx'][
0:agent_batch_size]
learner.priority_info_agent['replay_unique_id'] = learner.priority_info['replay_unique_id'][
0:agent_batch_size]
learner.priority_info_expert['priority'] = learner.priority_info['priority'][agent_batch_size:]
learner.priority_info_expert['replay_buffer_idx'] = learner.priority_info['replay_buffer_idx'][
agent_batch_size:]
learner.priority_info_expert['replay_unique_id'] = learner.priority_info['replay_unique_id'][
agent_batch_size:]
# Expert data and demo data update their priority separately.
replay_buffer.update(learner.priority_info_agent)
expert_buffer.update(learner.priority_info_expert)
3. For expert demonstration samples and agent experience samples, we add a key is_expert to the original data to distinguish them. If it is an expert demonstration sample, this key value is 1.
If it is an agent experience sample, this key value is 0,
# If it is an expert demonstration sample, this key value is 1,
for i in range(len(expert_data)):
# for rnn/sequence-based alg.
expert_data[i]['is_expert'] = [1] * expert_cfg.policy.collect.unroll_len
...
# If it is an agent experience sample, this key value is 0
for i in range(len(new_data)):
new_data[i]['is_expert'] = [0] * expert_cfg.policy.collect.unroll_len
Pre-training. Before the agent interacts with the environment, we can use the expert demo samples to pre-train the Q network, hoping to get a good initialization parameter to speed up the subsequent training process.
for _ in range(cfg.policy.learn.per_train_iter_k): # pretrain
if evaluator.should_eval(learner.train_iter):
stop, reward = evaluator.eval(learner.save_checkpoint, learner.train_iter, collector.envstep)
if stop:
break
# Learn policy from collected demo data
# Expert_learner will train ``update_per_collect == 1`` times in one iteration.
train_data = expert_buffer.sample(learner.policy.get_attribute('batch_size'), learner.train_iter)
learner.train(train_data, collector.envstep)
if learner.policy.get_attribute('priority'):
expert_buffer.update(learner.priority_info)
Implementations¶
of r2d3’s policy R2D3Policy is defined as follows:
- class ding.policy.r2d3.R2D3Policy(cfg: EasyDict, model: Module | None = None, enable_field: List[str] | None = None)[source]
- Overview:
Policy class of r2d3, from paper Making Efficient Use of Demonstrations to Solve Hard Exploration Problems .
- Config:
ID
Symbol
Type
Default Value
Description
Other(Shape)
1
typestr
dqn
RL policy register name, refer toregistryPOLICY_REGISTRYThis arg is optional,a placeholder2
cudabool
False
Whether to use cuda for networkThis arg can be diff-erent from modes3
on_policybool
False
Whether the RL algorithm is on-policyor off-policy4
prioritybool
False
Whether use priority(PER)Priority sample,update priority5
priority_IS_weightbool
False
Whether use Importance Sampling Weightto correct biased update. If True,priority must be True.6
discount_factorfloat
0.997, [0.95, 0.999]
Reward’s future discount factor, aka.gammaMay be 1 when sparsereward env7
nstepint
3, [3, 5]
N-step reward discount sum for targetq_value estimation8
burnin_stepint
2
The timestep of burnin operation,which is designed to RNN hidden statedifference caused by off-policy9
learn.updateper_collectint
1
How many updates(iterations) to trainafter collector’s one collection. Onlyvalid in serial trainingThis args can be varyfrom envs. Bigger valmeans more off-policy10
learn.batch_sizeint
64
The number of samples of an iteration11
learn.learning_ratefloat
0.001
Gradient step length of an iteration.12
learn.value_rescalebool
True
Whether use value_rescale function forpredicted value13
learn.target_update_freqint
100
Frequence of target network update.Hard(assign) update14
learn.ignore_donebool
False
Whether ignore done for target valuecalculation.Enable it for somefake termination env15
collect.n_sampleint
[8, 128]
The number of training samples of acall of collector.It varies fromdifferent envs16
collect.unroll_lenint
1
unroll length of an iterationIn RNN, unroll_len>1
- _forward_learn(data: dict) Dict[str, Any][source]
- Overview:
Forward and backward function of learn mode. Acquire the data, calculate the loss and optimize learner model.
- Arguments:
- data (
dict): Dict type data, including at least [‘main_obs’, ‘target_obs’, ‘burnin_obs’, ‘action’, ‘reward’, ‘done’, ‘weight’]
- data (
- Returns:
- info_dict (
Dict[str, Any]): Including cur_lr and total_loss cur_lr (
float): Current learning ratetotal_loss (
float): The calculated loss
- info_dict (
of dqfd’s loss function nstep_td_error_with_rescale is defined as follows:
- ding.rl_utils.td.dqfd_nstep_td_error_with_rescale(data: ~collections.namedtuple, gamma: float, lambda_n_step_td: float, lambda_supervised_loss: float, lambda_one_step_td: float, margin_function: float, nstep: int = 1, cum_reward: bool = False, value_gamma: ~torch.Tensor | None = None, criterion: <module 'torch.nn.modules' from '/home/docs/checkouts/readthedocs.org/user_builds/di-engine-docs/envs/latest/lib/python3.9/site-packages/torch/nn/modules/__init__.py'> = MSELoss(), trans_fn: ~typing.Callable = <function value_transform>, inv_trans_fn: ~typing.Callable = <function value_inv_transform>) Tensor[source]
- Overview:
Multistep n step td_error + 1 step td_error + supervised margin loss or dqfd
- Arguments:
data (
dqfd_nstep_td_data): The input data, dqfd_nstep_td_data to calculate lossgamma (
float): Discount factorcum_reward (
bool): Whether to use cumulative nstep reward, which is figured out when collecting datavalue_gamma (
torch.Tensor): Gamma discount value for target q_valuecriterion (
torch.nn.modules): Loss function criterionnstep (
int): nstep num, default set to 10
- Returns:
loss (
torch.Tensor): Multistep n step td_error + 1 step td_error + supervised margin loss, 0-dim tensortd_error_per_sample (
torch.Tensor): Multistep n step td_error + 1 step td_error + supervised margin loss, 1-dim tensor
- Shapes:
data (
q_nstep_td_data): The q_nstep_td_data containing [‘q’, ‘next_n_q’, ‘action’, ‘next_n_action’, ‘reward’, ‘done’, ‘weight’ , ‘new_n_q_one_step’, ‘next_n_action_one_step’, ‘is_expert’]q (
torch.FloatTensor): \((B, N)\) i.e. [batch_size, action_dim]next_n_q (
torch.FloatTensor): \((B, N)\)action (
torch.LongTensor): \((B, )\)next_n_action (
torch.LongTensor): \((B, )\)reward (
torch.FloatTensor): \((T, B)\), where T is timestep(nstep)done (
torch.BoolTensor) \((B, )\), whether done in last timesteptd_error_per_sample (
torch.FloatTensor): \((B, )\)new_n_q_one_step (
torch.FloatTensor): \((B, N)\)next_n_action_one_step (
torch.LongTensor): \((B, )\)is_expert (
int) : 0 or 1
Note
The input of the network in our current r2d3 policy implementation is only the state observation at time t, not including the action and reward at time t-1, nor the extra information vector \(f_{t}\) .
Benchmark Algorithm Performance¶
We conducted a series of comparative experiments in the PongNoFrameskip-v4 environment to verify: 1. The proportion of expert samples in a mini-batch used for training pho, 2. The proportion of expert demonstrations, 3. Whether to use pre-training The effect of different parameter settings such as l2 regularization on the final performance of the r2d3 algorithm.
Note
Our expert data is generated via ppo_offpolicy_collect_traj.py , Its expert model comes from the expert model obtained after the r2d2 algorithm is trained to converge on this environment. All experiments below seed=0.
The r2d2 baseline algorithm setting is recorded as r2d2_n5_bs2_ul40_upc8_tut0.001_ed1e5_rbs1e5_bs64, where:
n means nstep,
bs for burnin_step,
ul means unroll_len,
upc means update_per_collect,
tut means target_update_theta,
ed means eps_decay,
rbs means replay_buffer_size,
bs means batch_size,
See r2d2 pong config for details.
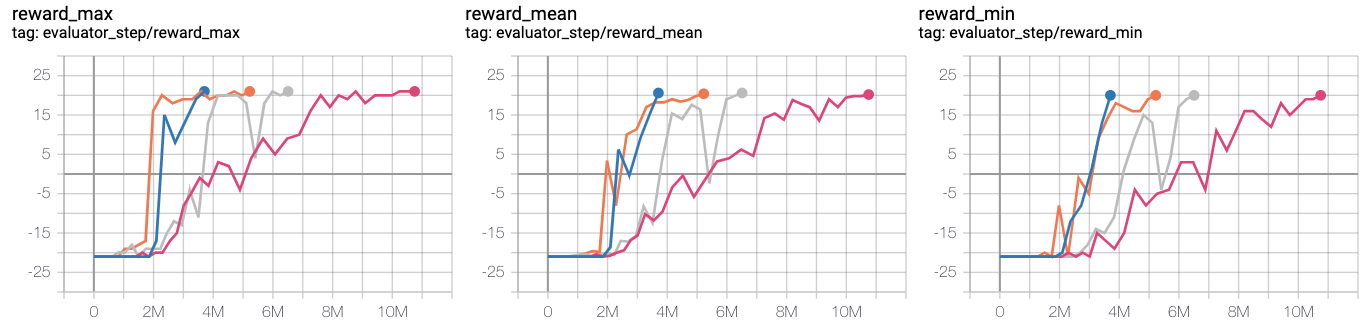
- Test the effect of the proportion of expert samples in a mini-batch used for training. Observation 1: pho needs to be moderate, take 1/4
blue line pong_r2d2_rbs1e4
orange line pong_r2d3_r2d2expert_k0_pho1-4_rbs1e4_1td_l2_ds5e3
grey line pong_r2d3_r2d2expert_k0_pho1-16_rbs1e4_1td_l2_ds5e3
red line pong_r2d3_r2d2expert_k0_pho1-2_rbs1e4_1td_l2_ds5e3
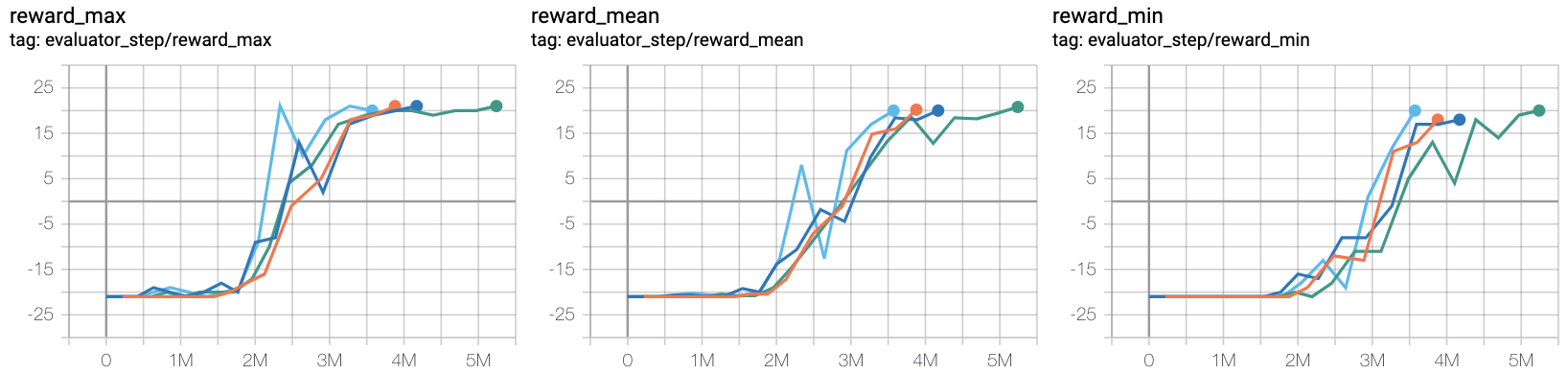
- Test the effect of the size of the total expert sample pool. Observation 2: The demo size needs to be moderate, take 5e3
orange line pong_r2d2_rbs2e4
azure line pong_r2d3_r2d2expert_k0_pho1-4_rbs2e4_1td_l2_ds5e3
blue line pong_r2d3_r2d2expert_k0_pho1-4_rbs2e4_1td_l2_ds1e3
Green line pong_r2d3_r2d2expert_k0_pho1-4_rbs2e4_1td_l2_ds1e4
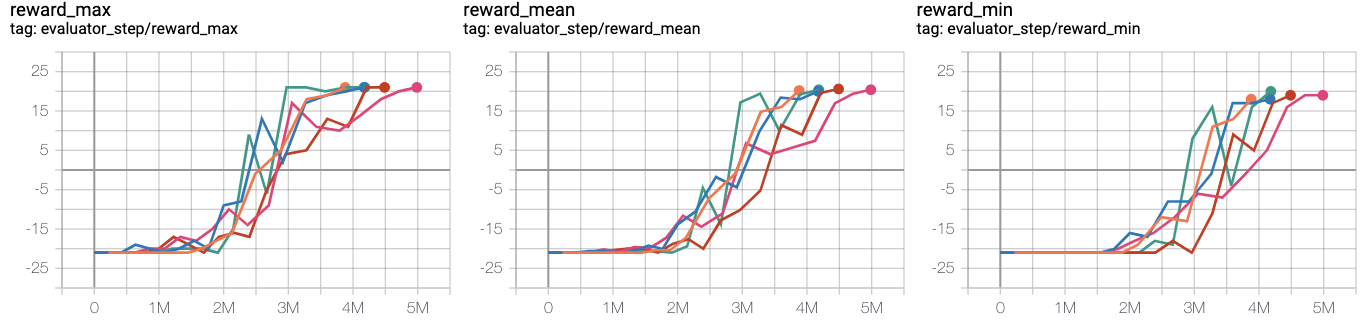
- Test if pretrained and the effect of L2 regularization. Observation 3: Pre-training and L2 regularization have little effect
Orange line r2d2_rbs2e4_rbs2e4
blue line pong_r2d3_r2d2expert_k0_pho1-4_rbs2e4_1td_l2
pink line pong_r2d3_r2d2expert_k0_pho1-4_rbs2e4_1td_nol2
Crimson line pong_r2d3_r2d2expert_k100_pho1-4_rbs2e4_1td_l2
Green line pong_r2d3_r2d2expert_k100_pho1-4_rbs2e4_1td_nol2
References¶
Paine T L, Gulcehre C, Shahriari B, et al. Making efficient use of demonstrations to solve hard exploration problems[J]. arXiv preprint arXiv:1909.01387, 2019.
Kapturowski S, Ostrovski G, Quan J, et al. Recurrent experience replay in distributed reinforcement learning[C]. International conference on learning representations(LCLR). 2018.
Badia A P, Sprechmann P, Vitvitskyi A, et al. Never give up: Learning directed exploration strategies[J]. arXiv preprint arXiv:2002.06038, 2020.
Burda Y, Edwards H, Storkey A, et al. Exploration by random network distillation[J]. https://arxiv.org/abs/1810.12894v1. arXiv:1810.12894, 2018.
Pathak D, Agrawal P, Efros A A, et al. Curiosity-driven exploration by self-supervised prediction[C]. International conference on machine learning(ICML). PMLR, 2017: 2778-2787.
Piot, B.; Geist, M.; and Pietquin, O. 2014a. Boosted bellman residual minimization handling expert demonstrations. In European Conference on Machine Learning (ECML).