Google Research Football (Gfootball)¶
Overview¶
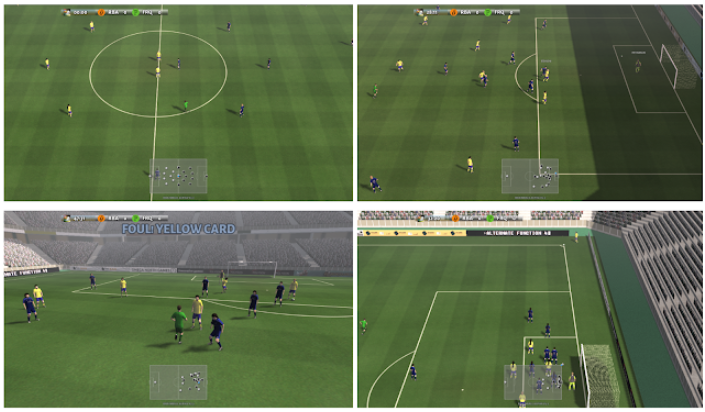
Google Research Football (hereinafter referred to as Gfootball) is a football environment suitable for reinforcement learning research created by the Google team on the basis of the open source football game GamePlay Football. Compatible with OpenAI Gym API, it can not only be used for agent training, but also allows players to play games with built-in AI or trained agents with keyboard or gamepad input. The image below shows the rendered Gfootball game environment.
Installation¶
Dependency package
Linux
sudo apt-get install git cmake build-essential libgl1-mesa-dev libsdl2-dev \
libsdl2-image-dev libsdl2-ttf-dev libsdl2-gfx-dev libboost-all-dev \
libdirectfb-dev libst-dev mesa-utils xvfb x11vnc python3-pip
python3 -m pip install --upgrade pip setuptools psutil wheel
MacOS
brew install git python3 cmake sdl2 sdl2_image sdl2_ttf sdl2_gfx boost boost-python3
python3 -m pip install --upgrade pip setuptools psutil wheel
Windows
python -m pip install --upgrade pip setuptools psutil wheel
Enviroment of installing gfootball
Install from pip
python3 -m pip install gfootball
Intall from github orgin code
git clone https://github.com/google-research/football.git
cd football
python3 -m pip install .
Validation of the environment installation
python3 -m gfootball.play_game --action_set=full
Enter the following game interface to prove that the installation is successful.
For more installation environment related issues, please refer to Gfootball official website github. In addition, the official also provides a docker image for deploying the environment in the docker environment, you can refer to the docker deployment document .
Environment Creation API¶
After importing and creating the environment successfully, you can interact with the environment through the same code as openAI gym:
import gfootball.env as football_env
env = football_env.create_environment(
env_name='11_vs_11_stochastic',
representation='raw',
stacked=False,
logdir='/tmp/football',
write_goal_dumps=False,
write_full_episode_dumps=False,
write_video=False,
render=False,
number_of_right_players_agent_controls=1
)
env.reset()
obs = env.observations()
action = get_action(obs) # your model
next_obs, reward, done, info = env.step(action)
The API for creating an environment is as follows:
env name. The core parameters determine the scene created by the environment. Commonly used are 11 vs 11 stochastic, 11 vs 11 easy stochastic, 11 vs 11 hard stochastic, which correspond to the three difficulty levels of medium, easy and hard games. The complete 90-minute soccer game with built-in bots. In addition, there are also scenarios such as academy run pass and shoot with keeper, see documentation for details.
Representation。The representation type of the environment output, raw is the original vector input, such as player position, ball speed and other information, pixels is the original image pixel input, and the official also provides some existing environment input packages.
stacked。Whether to stack frame inputs.
logdir。The path to save the log file.
write_goal_dumps。Whether or not to save the binary file of the time of the goal for generating the video playback.
write_full_episode_dumps。 Whether to save the entire binary file for generating video playback.
write_video。 Whether or not to save the binary file of the time of the goal for generating the video playback.
render。Whether to generate a full video of the rendering.
number_of_right_players_agent_controls。Select the number of players to control at the same time.
It is also possible to use environments encapsulated by DI-engine:
### Game built-in bot environment
from dizoo.gfootball.envs.gfootball_env import GfootballEnv
env = GfootballEnv({})
### self play environment
from dizoo.gfootball.envs.gfootballsp_env import GfootballEnv
env = GfootballEnv({})
State Space¶
Generally use raw input information
Ball Information:
ball- [x, y, z] coordinates.ball_direction- [x, y, z]The direction of the ball’s velocity.ball_rotation- [x, y, z] The rotation direction of the ball.ball_owned_team- {-1, 0, 1}, -1 = ball not owned by team, 0 = left team, 1 = right team.。ball_owned_player- {0..N-1} indicates which player the ball is held by.
Left team information:
left_team- N*2dimensional vector [x, y], indicating player positions.left_team_direction- N*2 dimensional vector [x, y],indicating the direction of the player’s velocity.left_team_tired_factor- N dimensional vector indicating player fatigue. 0means no fatigue at all.left_team_yellow_card- N dimensional vector indicating whether the player has a yellow card.left_team_active- N dimensional vector indicating whether the player has no red cards.left_team_roles- N dimensional vector indicating player roles:0= ePlayerRoleGK - goalkeeper,1= ePlayerRoleCB - centre back,2= ePlayerRoleLB - left back,3= ePlayerRoleRB - right back,4= ePlayerRoleDM - defence midfield,5= ePlayerRoleCM - central midfield,6= ePlayerRoleLM - left midfield,7= ePlayerRoleRM - right midfield,8= ePlayerRoleAM - attack midfield,9= ePlayerRoleCF - central front,
Right team information: Symmetrical with left team
Control player information:
active- {0..N-1} indicates the controlling player number.designated- {0..N-1} indicates the dribbler number.sticky_actions- 10dimensional vector indicating whether the following actions can be performed:0-action_left1-action_top_left2-action_top3-action_top_right4-action_right5-action_bottom_right6-action_bottom7-action_bottom_left8-action_sprint9-action_dribble
match information
score- the score.steps_left- the number of steps remaining (3000 steps in the global game).game_mode - game state information:
0=e_GameMode_Normal1=e_GameMode_KickOff2=e_GameMode_GoalKick3=e_GameMode_FreeKick4=e_GameMode_Corner5=e_GameMode_ThrowIn6=e_GameMode_Penalty
Image: Game image information in RGB.
DI-engine encapsulated state space
Players: 29 dimensionsavail, actionable actions (10-dimensional one-hot, long pass, high foot, short pass, shot, sprint, stop motion, stop sprint,Slide tackle, dribble, stop dribble) (Ref #6)[player_pos_x, player_pos_y], the current control player position (2D coordinates)player_direction*100, currently controls the player’s movement direction (2D coordinates)*player_speed*100, currently controls player speed (1D scalar)layer_role_onehot, the currently controlling player role (10-dimensional one-hot)[ball_far, player_tired, is_dribbling, is_sprinting], whether the ball is too far, currently controlling the ball | Player fatigue, whether they are dribbling, whether they are sprinting (4-dimensional 0/1)
Ball: 18 dimensionsobs['ball'], ball position (3D coordinates)ball_which_zone,the artificially defined area where the ball is located (6-dimensional one-hot)[ball_x_relative, ball_y_relative],the distance between the ball and the currently controlled player’s x, y axis (2 dimensions)obs['ball_direction']*20,the direction of the ball movement (3D coordinates)*[ball_speed*20, ball_distance, ball_owned, ball_owned_by_us],ball speed, nowControl the distance of the player, whether the ball is controlled, whether the ball is controlled by us(4 dimension)
LeftTeam: 7dimensions. The following information for all our players (10*7)LeftTeamCloset:7 dimensions.The position of our player closest to the player currently in control(2 dimension)
Velocity vector of our player closest to the currently controlled player(2 dimension)
The current control player’s speed of the nearest allied player(1 dimension)
The distance of the currently controlled player to the nearest allied player(1 dimension)
Fatigue of allied players closest to the currently controlled player(1 dimension)
RightTeam:7 dimension。The following information for all opposing players(11*7)RightTeamCloset:7 dimensionThe position of our player closest to the player currently in control(2 dimension)
Velocity vector of our player closest to the currently controlled player (2 dimension)
Speed of the opposing player closest to the player currently in control (1 dimension)
Distance to the closest opposing player to the player currently in control(1 dimension)
Fatigue of the opposing player closest to the player currently in control(1 dimension)
Action Space¶
Gfootball’s action space is a 19-dimensional discrete action:
stateless actions
action_idle= 0, an empty action.
Move actions (both sticky actions)
action_left= 1, left.action_top_left= 2, top right.action_top= 3, up.action_top_right= 4, top right.action_right= 5, right.action_bottom_right= 6, bottom right.action_bottom= 7, down.action_bottom_left= 8, bottom left.
Pass/shoot action
action_long_pass= 9, long pass.action_high_pass= 10, high pass.action_short_pass= 11, short pass.action_shot= 12, shot.
other
action_sprint= 13, sprint.action_release_direction= 14, releases sticky actions (like moving).action_release_sprint= 15, stop sprinting.action_sliding= 16, sliding tackle (only available without the ball).action_dribble= 17, dribble.action_release_dribble= 18, stop dribble.
DI-zoo Runnable Code Example¶
See DI-zoo gfootball for the complete training entry. The configuration file for self-play training with ppo-lstm is as follows.
from easydict import EasyDict
from ding.config import parallel_transform
from copy import deepcopy
from ding.entry import parallel_pipeline
gfootball_ppo_config = dict(
env=dict(
collector_env_num=1,
collector_episode_num=1,
evaluator_env_num=1,
evaluator_episode_num=1,
stop_value=5,
save_replay=False,
render=False,
),
policy=dict(
cuda=False,
model=dict(type='conv1d', import_names=['dizoo.gfootball.model.conv1d.conv1d']),
nstep=1,
discount_factor=0.995,
learn=dict(
batch_size=32,
learning_rate=0.001,
learner=dict(
learner_num=1,
send_policy_freq=1,
),
),
collect=dict(
n_sample=20,
env_num=1,
collector=dict(
collector_num=1,
update_policy_second=3,
),
),
eval=dict(evaluator=dict(eval_freq=50), env_num=1),
other=dict(
eps=dict(
type='exp',
start=0.95,
end=0.1,
decay=100000,
),
replay_buffer=dict(
replay_buffer_size=100000,
enable_track_used_data=True,
),
commander=dict(
collector_task_space=2,
learner_task_space=1,
eval_interval=5,
league=dict(),
),
),
)
)
gfootball_ppo_config = EasyDict(gfootball_ppo_config)
main_config = gfootball_ppo_config
gfootball_ppo_create_config = dict(
env=dict(
import_names=['dizoo.gfootball.envs.gfootballsp_env'],
type='gfootball_sp',
),
env_manager=dict(type='base'),
policy=dict(type='ppo_lstm_command', import_names=['dizoo.gfootball.policy.ppo_lstm']),
learner=dict(type='base', import_names=['ding.worker.learner.base_learner']),
collector=dict(
type='marine',
import_names=['ding.worker.collector.marine_parallel_collector'],
),
commander=dict(
type='one_vs_one',
import_names=['ding.worker.coordinator.one_vs_one_parallel_commander'],
),
comm_learner=dict(
type='flask_fs',
import_names=['ding.worker.learner.comm.flask_fs_learner'],
),
comm_collector=dict(
type='flask_fs',
import_names=['ding.worker.collector.comm.flask_fs_collector'],
),
)
gfootball_ppo_create_config = EasyDict(gfootball_ppo_create_config)
create_config = gfootball_ppo_create_config
gfootball_ppo_system_config = dict(
path_data='./data',
path_policy='./policy',
communication_mode='auto',
learner_multi_gpu=False,
learner_gpu_num=1,
coordinator=dict()
)
gfootball_ppo_system_config = EasyDict(gfootball_ppo_system_config)
system_config = gfootball_ppo_system_config
if __name__ == '__main__':
config = tuple([deepcopy(main_config), deepcopy(create_config), deepcopy(system_config)])
parallel_pipeline(config, seed=0)
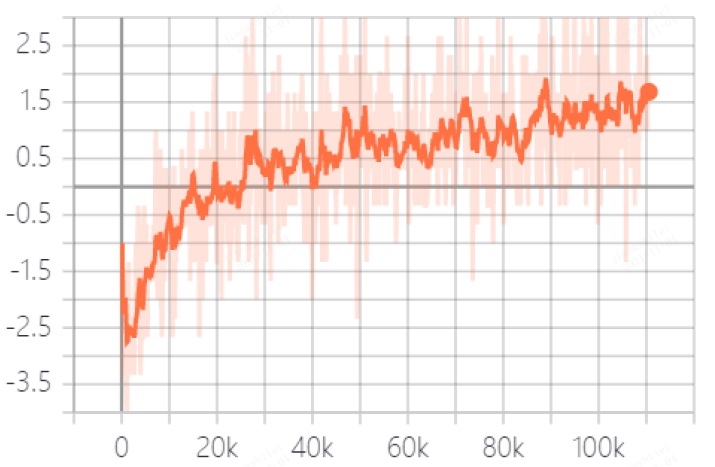
Training Example¶
In the state space of DI-engine, after reward design and action space constraints, the winning rate curve of built-in hard AI in self play training is shown in the following figure: