LunarLander¶
Overview¶
LunarLander, or Lunar Landing, is a mission aimed at navigating a lander to a designated landing site. The environment has both discrete action space and continuous action space versions. Currently, DI-engine only supports the discrete action space version, and the continuous space version and some adaptations will be added in the future. The following mainly introduces the offline action space version of lunarlander.

Install¶
Installation Method¶
Just install the gym and Box2d libraries. Users can choose to install them with one click through pip
Note: If the user does not have root privileges, please add –user after the install command
# Install Directly
pip install gym
pip install Box2D
Verify Installation¶
After the installation is complete, you can verify that the installation was successful by running the following command on the Python command line:
import gym
env = gym.make('LunarLander-v2')
obs = env.reset()
print(obs.shape) # (8,)
env = gym.make('LunarLanderContinuous-v2')
obs = env.reset()
print(obs.shape) # (8,)
Image¶
The image of DI-engine is equipped with the framework itself and the Lunarlander environment, which can be obtained by docker pull opendilab/ding:nightly, or by visiting docker
hub for more images
Space before Transformation (Original Environment)¶
Observation Space¶
np array with 8-latitude observation space, data type
float32s[0] is the abscissa
s[1] is the ordinate
s[2] is the horizontal speed
s[3] is the vertical speed
s[4] is radians from the ordinate (positive to the right, negative to the left, 180 degrees = pi radians)
s[5] is the angular velocity
s[6] 1 if one foot lands, 0 otherwise
s[7] 1 if the second foot lands, 0 otherwise
Action Space¶
For the game operation key space of the discrete version of lunarlander, it is generally a discrete action space of size 4, and the data type is
intIn the discrete version of lunarlander, actions take values in 0-3, the specific meanings are:
0: Do nothing
1: Fire right engine
2: Fire down engine
3: Fire left engine
Reward Space¶
a
intvalueThe reward for moving from the top of the screen to the landing point and going to zero speed is about 100…140 points. If the lander travels in a direction away from the landing pad, it loses the reward. If the lander falls or stops, the episode ends, earning an extra -100 or +100 points. Ground contact for each leg is a +10 bonus. The launch main engine is -0.3 bonus per frame. A successful landing to the landing site is 200 points. Landing outside the landing gear is possible. Fuel is unlimited.
Other¶
The end of the game is the end of the current environment episode. If the lander crashes or reaches a stationary state, the current episode ends
Key Facts¶
Discrete and continuous action spaces
Transformed Space (RL Environment)¶
Observation Space¶
no change
Action Space¶
It is still a discrete action space of size 4, but the data type is changed from
inttonp.int64, the size is( ), that is, an array of 0-dim
Reward Space¶
Transformation content: data structure transformation
Transformation result: it becomes an np array, the size is
(1, ), and the data type isnp.float64
The above space can be expressed as:
import gym
obs_space = gym.spaces.spaces.Box(-np.inf, np.inf, shape=(8,), dtype=np.float32)
act_space = gym.spaces.Discrete(4)
Other¶
The
inforeturned by the environmentstepmethod must contain theeval_episode_returnkey-value pair, which represents the evaluation index of the entire episode, and is the cumulative sum of the rewards of the entire episode in lunarlander
Other¶
Lazy Initialization¶
In order to support parallel operations such as environment vectorization, environment instances generally implement lazy initialization, that is, the __init__method does not initialize the real original environment instance, but only sets relevant parameters and configuration values. The concrete original environment instance is initialized when the resetmethod is used.
Random Seed¶
There are two parts of random seeds in the environment that need to be set, one is the random seed of the original environment, and the other is the random seed of the random library used by various environment transformations (such as
random,np.random)For the environment caller, just set these two seeds through the
seedmethod of the environment, and do not need to care about the specific implementation detailsConcrete implementation inside the environment: For the seed of the original environment, set before calling the
resetmethod of the environment, before the concreteresetThe specific implementation inside the environment: for random library seeds, set the value directly in the
seedmethod of the environment; for the seed of the original environment, inside theresetmethod of the calling environment, The specific original environmentresetwas previously set to seed + np_seed, where seed is the value of the aforementioned random library seed, np_seed = 100 * np.random.randint(1, 1000).
The difference between training and testing environments¶
The training environment uses a dynamic random seed, that is, the random seed of each episode is different, and is generated by a random number generator, but the seed of this random number generator is fixed by the
seedmethod of the environment ;The test environment uses a static random seed, that is, the random seed of each episode is the same, specified by theseedmethod.
Store Video¶
After the environment is created, but before reset, call the enable_save_replaymethod to specify the path to save the game recording. The environment will automatically save the local video files after each episode ends. (The default call gym.wrappers.RecordVideoimplementation), the code shown below will run an environment episode and save the result of this episode in a folder ./video/:
from easydict import EasyDict
from dizoo.box2d.lunarlander.envs import LunarLanderEnv
env = LunarLanderEnv({})
env.enable_save_replay(replay_path='./video')
obs = env.reset()
while True:
action = env.random_action()
timestep = env.step(action)
if timestep.done:
print('Episode is over, eval episode return is: {}'.format(timestep.info['eval_episode_return']))
break
DI-zoo Runnable Code Example¶
The full training configuration file is at github
link
Inside, for specific configuration files, such as lunarlander_dqn_config.py, use the following demo to run:
from easydict import EasyDict
from ding.entry import serial_pipeline
nstep = 3
lunarlander_dqn_default_config = dict(
env=dict(
# Whether to use shared memory. Only effective if "env_manager_type" is 'subprocess'
manager=dict(shared_memory=True, ),
# Env number respectively for collector and evaluator.
collector_env_num=8,
evaluator_env_num=5,
n_evaluator_episode=5,
stop_value=200,
),
policy=dict(
# Whether to use cuda for network.
cuda=False,
model=dict(
obs_shape=8,
action_shape=4,
encoder_hidden_size_list=[512, 64],
# Whether to use dueling head.
dueling=True,
),
# Reward's future discount factor, aka. gamma.
discount_factor=0.99,
# How many steps in td error.
nstep=nstep,
# learn_mode config
learn=dict(
update_per_collect=10,
batch_size=64,
learning_rate=0.001,
# Frequency of target network update.
target_update_freq=100,
),
# collect_mode config
collect=dict(
# You can use either "n_sample" or "n_episode" in collector.collect.
# Get "n_sample" samples per collect.
n_sample=64,
# Cut trajectories into pieces with length "unroll_len".
unroll_len=1,
),
# command_mode config
other=dict(
# Epsilon greedy with decay.
eps=dict(
# Decay type. Support ['exp', 'linear'].
type='exp',
start=0.95,
end=0.1,
decay=50000,
),
replay_buffer=dict(replay_buffer_size=100000, )
),
),
)
lunarlander_dqn_default_config = EasyDict(lunarlander_dqn_default_config)
main_config = lunarlander_dqn_default_config
lunarlander_dqn_create_config = dict(
env=dict(
type='lunarlander',
import_names=['dizoo.box2d.lunarlander.envs.lunarlander_env'],
),
env_manager=dict(type='subprocess'),
policy=dict(type='dqn'),
)
lunarlander_dqn_create_config = EasyDict(lunarlander_dqn_create_config)
create_config = lunarlander_dqn_create_config
if __name__ == "__main__":
serial_pipeline([main_config, create_config], seed=0)
Benchmark Algorithm Performance¶
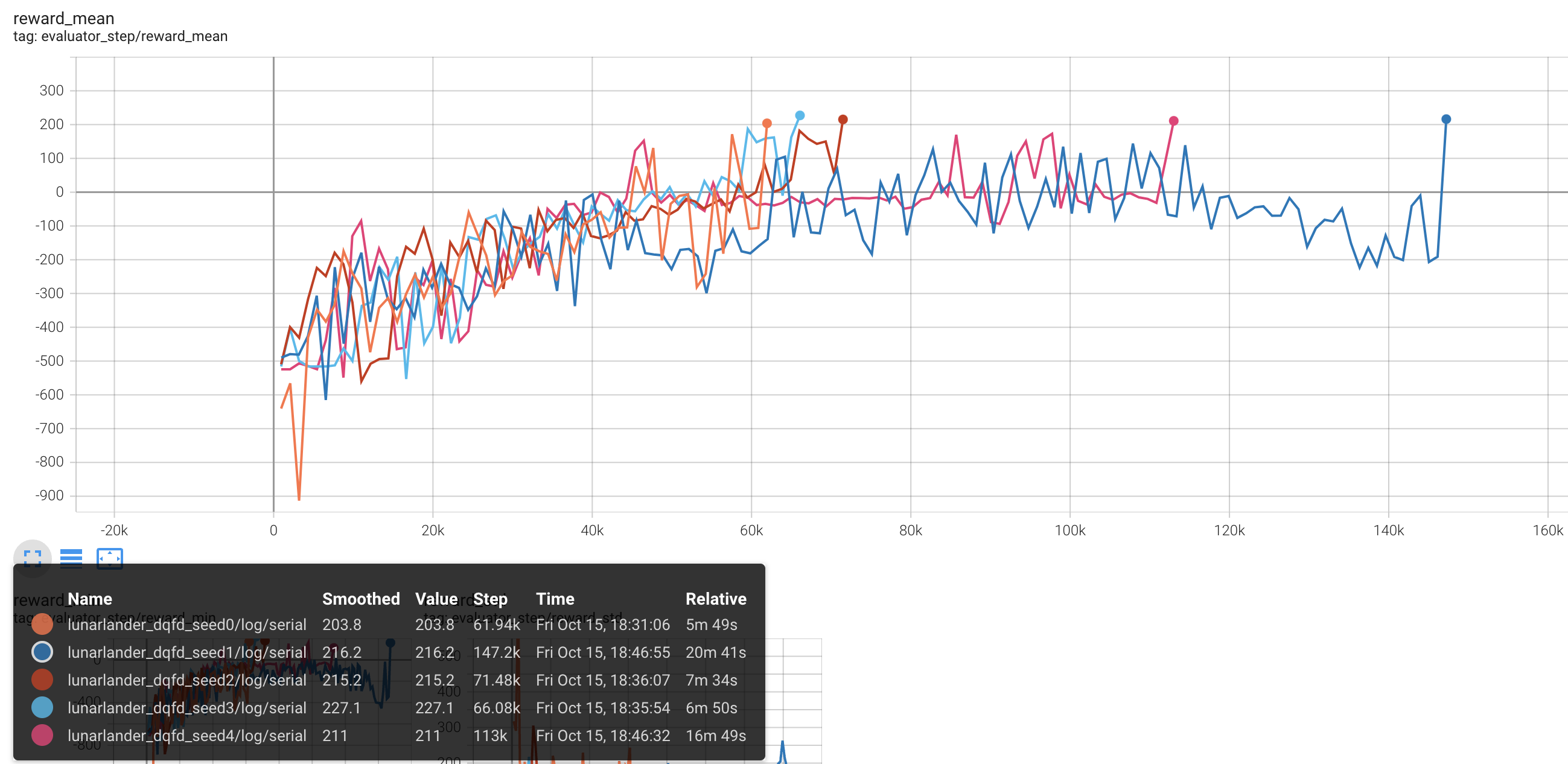
LunarLander (Average reward greater than or equal to 200 is considered a better Agent)
Lunarlander + DQFD