PettingZoo¶
Overview¶
PettingZoo is a Python zoo for studying multi-agent reinforcement learning,It can be considered as a multi-agent version of Gym。It contains the following environment families:
Atari:Multiplayer Atari 2600 game, including cooperative, competitive and hybrid scenarios
Butterfly:a highly coordinated cooperative graphics game developed by the PettingZoo team
Classic:Classic games, including cards, board games and so on
MAgent:Configurable environment with a large number of particle agents, from https://github.com/geek-ai/MAgent
MPE:A simple set of non-graphical communication tasks, derived from https://github.com/openai/multiagent-particle-envs
SISL:3 collaborative environments from https://github.com/sisl/MADRL
The following figure shows the mpe_simple_spread environment in it:

Note
It should be noted that PettingZoo maintains strict version management for reproducibility. All environments end with a suffix like_v0 . When the environment changes that could affect the learning outcome, the number is incremented by one_v0->_v1 to prevent potential confusion.
Installation¶
Installation Method¶
Currently PettingZoo officially supports Python 3.7~3.9 on Linux and macOS。
It can be installed directly through pip; in addition, since PettingZoo is used in unit tests in DI-engine, installing DI-engine will also install PettingZoo by default:
# Method1: Install directly with pip
pip install pettingzoo
# Method2: Just install DI-engine
pip install DI-engine
Since PettingZoo contains a lot of environments, different environments have different installation conditions on different systems. Therefore the above installation does not contain all dependencies of all environment families. For a specific environment family dependency, you can install it like this:
# install Atari family dependency
pip install pettingzoo[atari]
# or install all dependencies
pip install pettingzoo[all]
Verify Installation¶
After the installation is complete, run the following Python program. If no error is reported, the installation is successful.
from pettingzoo.mpe import simple_spread_v2
env = simple_spread_v2.parallel_env()
obs = env.reset()
print(obs[env.agents[0]]) # (18,)
Image¶
DI-engine has an image ready with the framework itself and the PettingZoo environment, available via docker pull opendilab/ding:nightly, or by visiting docker
hub Get more images
Space Before Transformation (Original Environment)¶
Since PettingZoo includes many families of environments, each of which is unique, it is difficult to cover everything. Here is an example of the Simple Spread environment in MPE.
Note
Simple Spread game‘s goal is to want agents to cover all landmarks while avoiding collisions with each other.
Observation Space¶
The agent’s observations are made by
the current agent’s velocity,self.vel, (2,)
the current agent’s position,self.pos, (2,)
The relative position of the landmark, landmark_rel_positions,landmark_rel_positions, (n_landmarks * 2,)
the relative positions of other agents, other_agent_rel_positions,other_agent_rel_positions, ((n_agents-1) * 2,)
Communication between other agents and the current agent, communication, ((n_agents-1) * 2,)
The specific dimension is (2 + 2 + n_landmarks*2 + (n_agents-1)*2 + (n_agents-1)*2), and the data type is float32. For example, when you generate a simple spread environment with 5 agents (n_agents=5) and 5 landmarks (n_landmarks=5), each agent has an observation dimension of (30,)。
Action Space¶
No manual control
Discrete action space: The action space of each agent is the same, the size is
(5,), and the data type isgym.spaces.Discrete(5). The dimension of each specific action is (,), the data type isint, the specific meaning is to do nothing or move in four basic directions.Continuous action space: The action space of each agent is the same, and the data type is
gym.spaces.Box(0.0, 1.0, (5,)). The dimension of each specific action is (5,), the data type isarray, the specific meaning is to do nothing or enter a speed between 0.0 and 1.0 in each of the four cardinal directions, and Velocities in opposite directions can be superimposed.
from pettingzoo.mpe import simple_spread_v2
# discrete env
dis_env = simple_spread_v2.parallel_env(N=3, continuous_actions=False)
# continuous env
con_env = simple_spread_v2.parallel_env(N=3, continuous_actions=True)
dis_env.reset()
con_env.reset()
dis_env.action_space('agent_0').sample() # 2
con_env.action_space('agent_0').sample() # array([0.24120373, 0.83279127, 0.4586939 , 0.4208583 , 0.97381055], dtype=float32)
Reward Space¶
All agents contribute a global reward, based on the closest agent to each landmark, a
floatvalueSpecifically, all agents receive a global reward based on the distance of the nearest agent from each landmark (sum of minimum distances). Also, if agents collide with other agents, they will be penalized.
Others¶
The game will terminate after executing the number of cycles specified by the environment parameter
max_cycles. The default value for all environments is 25 cycles.
Key Facts¶
The input is state instead of raw pixel;
Either discrete action space or continuous action space can be selected;
There are both cooperative environments, such as
Simple Spread,Simple Speaker Listener, etc.; there are also competitive (competitive) environments, such asSimple Adversary,Simple Crypto.
Transformed Space (RL Environment)¶
Observation Space¶
For the multi-agent algorithm, according to the state before the transformation, the local agent_state and the global global_state are generated respectively:
Agent_State: shape: (n_agent, 2 + 2 + n_landmark * 2 + (n_agent - 1) * 2 + (n_agent - 1) * 2)
The state of the agent itself: speed, coordinates
The relative positions of other agents and landmarks
Communication from other agents
global_state: shape: (n_agent * (2 + 2) + n_landmark * 2 + n_agent * (n_agent - 1) * 2, )
The state of all agents: speed, coordinates
Location of all landmarks
Communication between all agents
If the environment parameter
action_specific_global_state=True,the global_state of each agent is different, which is obtained by concatenate its own agent_state and the original global_state.
Action Space¶
Discrete action space without transformation
ontinuous action space, if the environment variable
act_scale=True, the action value is affine transformed
Reward Space¶
No change,
gym.spaces.Box(low=float("-inf"), high=float("inf"), shape=(1, ), dtype=np.float32)
Others¶
Lazy Initialization¶
In order to facilitate parallel operations such as environment vectorization, environment instances generally implement lazy initialization, that is, the __init__method does not initialize the real original environment instance, but only sets relevant parameters and configuration values. The concrete original environment instance is initialized when theresetmethod is used.
Random Seed¶
There are two parts of random seeds in the environment that need to be set, one is the random seed of the original environment, and the other is the random seed of the random library used by various environment transformations (such as
random,np.random)For the environment caller, just set these two seeds through the
seedmethod of the environment, and do not need to care about the specific implementation detailsConcrete implementation inside the environment: For the seed of the original environment, set before calling the
resetmethod of the environment, before the concreteresetConcrete implementation inside the environment: For random library seeds, set the value directly in the
seedmethod of the environment
The Difference Between Training And Testing Environments¶
The training environment uses dynamic random seeds, that is, the random seeds of each episode are different, and they are all generated by a random number generator, but the seed of this random number generator is fixed by the
seedmethod of the environment; The test environment uses a static random seed, that is, the random seed of each episode is the same, specified by theseedmethod.
DI-Zoo Runnable Code Example¶
The full training profile is at github link
,or specific configuration files such as,such asptz_simple_spread_mappo_config.py,Use the following demo to run:
from easydict import EasyDict
n_agent = 3
n_landmark = n_agent
collector_env_num = 8
evaluator_env_num = 8
main_config = dict(
exp_name='ptz_simple_spread_mappo_seed0',
env=dict(
env_family='mpe',
env_id='simple_spread_v2',
n_agent=n_agent,
n_landmark=n_landmark,
max_cycles=25,
agent_obs_only=False,
agent_specific_global_state=True,
continuous_actions=False,
collector_env_num=collector_env_num,
evaluator_env_num=evaluator_env_num,
n_evaluator_episode=evaluator_env_num,
stop_value=0,
),
policy=dict(
cuda=True,
multi_agent=True,
action_space='discrete',
model=dict(
action_space='discrete',
agent_num=n_agent,
agent_obs_shape=2 + 2 + n_landmark * 2 + (n_agent - 1) * 2 + (n_agent - 1) * 2,
global_obs_shape=2 + 2 + n_landmark * 2 + (n_agent - 1) * 2 + (n_agent - 1) * 2 + n_agent * (2 + 2) +
n_landmark * 2 + n_agent * (n_agent - 1) * 2,
action_shape=5,
),
learn=dict(
multi_gpu=False,
epoch_per_collect=5,
batch_size=3200,
learning_rate=5e-4,
# ==============================================================
# The following configs is algorithm-specific
# ==============================================================
# (float) The loss weight of value network, policy network weight is set to 1
value_weight=0.5,
# (float) The loss weight of entropy regularization, policy network weight is set to 1
entropy_weight=0.01,
# (float) PPO clip ratio, defaults to 0.2
clip_ratio=0.2,
# (bool) Whether to use advantage norm in a whole training batch
adv_norm=False,
value_norm=True,
ppo_param_init=True,
grad_clip_type='clip_norm',
grad_clip_value=10,
ignore_done=False,
),
collect=dict(
n_sample=3200,
unroll_len=1,
env_num=collector_env_num,
),
eval=dict(
env_num=evaluator_env_num,
evaluator=dict(eval_freq=50, ),
),
other=dict(),
),
)
main_config = EasyDict(main_config)
create_config = dict(
env=dict(
import_names=['dizoo.petting_zoo.envs.petting_zoo_simple_spread_env'],
type='petting_zoo',
),
env_manager=dict(type='subprocess'),
policy=dict(type='ppo'),
)
create_config = EasyDict(create_config)
ptz_simple_spread_mappo_config = main_config
ptz_simple_spread_mappo_create_config = create_config
if __name__ == '__main__':
# or you can enter `ding -m serial_onpolicy -c ptz_simple_spread_mappo_config.py -s 0`
from ding.entry import serial_pipeline_onpolicy
serial_pipeline_onpolicy((main_config, create_config), seed=0)
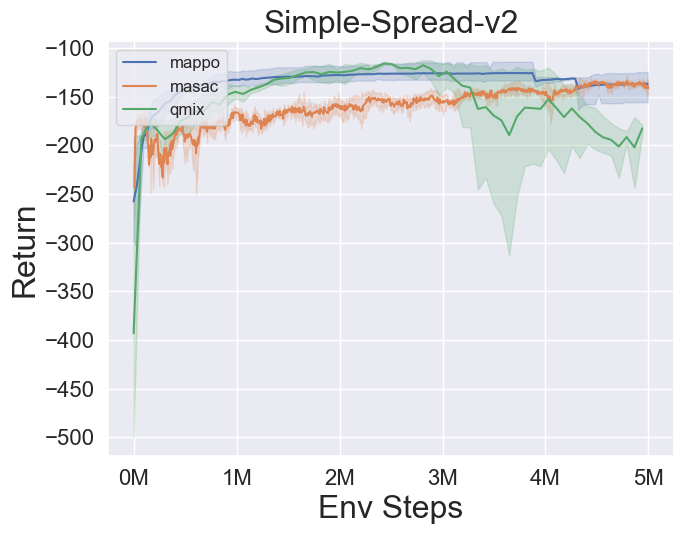
Benchmark Algorithm Performance¶
simple_spread_v2
qmix & masac & mappo