SMAC¶
Overview¶
SMAC is an environment for multi-agent collaborative reinforcement learning (MARL) on Blizzard StarCraft II. SMAC uses Blizzard StarCraft 2’s machine learning API and DeepMind’s PySC2 to provide a friendly interface for the interaction between agents and StarCraft 2, which is convenient for developers to observe and execute actions. Compared to PySC2, SMAC focuses on a decentralized micro-operation scheme, where each agent of the game is controlled by a separate RL agent.
Install¶
Installation Method¶
StarCraft 2 game and PySC2 library is needed , the installation method can refer to DI-star installation
The installation mainly consists of two parts:
1. Download the StarCraft 2 game For Linux system users, the installation path is https://github.com/Blizzard/s2client-proto#downloads, then use the export SC2PATH=<sc2/installation/path> command to add the installation path to the environment in variable For Windows system users, please refer to https://starcraft2.com for installation
Install PySC2 compatible with DI-engine
git clone https://github.com/opendilab/DI-star.git
cd DI-star
pip install -e .
Verify installation¶
After the installation is complete, you can confirm that the environment variable is set successfully by echo $SC2PATH after the installation is successful
Image¶
DI-engine’s mirror is equipped with the framework itself and the Smac environment, which can be obtained by docker pull opendilab/ding:nightly-smac, or by accessing docker
hubfor more mirror
Space before Transformation (Original Environment)¶
Observation Space¶
You can obtain fragmentary information such as whether each agent is alive, the remaining HP of each agent, allies or enemies within the vision range of each agent.
Action Space¶
The game operation button space, generally a discrete action space of size N (N varies with the specific sub-environment), the data type is
int, you need to pass in python values (or 0-dimensional np arrays, such as actions 3 isnp.array(3)For each map, the action space N is generally equal to 6 + the number of enemies, such as 14 in the 3s5z map and 70 in the 2c_vs_64zg map. The specific meaning is:
0: NOOP
1: STOP
2: MOVE_NORTH
3: MOVE_SOUTH
4: MOVE_EAST
5: MOVE_WEST
6 - N: ATTACK ENEMY, the ID of the attacked enemy is N-6
Reward Space¶
The game wins or loses, the victory is 1, and the defeat is 0, which is generally an
intvalue.
Other¶
The end of the game is the end of the current environment episode
Quick Facts¶
The input is information after combining discrete information
Discrete action space
The reward is a sparse reward. We set fake_reward so that the reward used during training is a dense reward.
Transformed Space (RL Environment)¶
Observation Space¶
Transformation content: splicing various discrete information seen by each agent, and using the spliced information as the agent_state seen by each agent and the global global_state
Transformation result: a dict type data, which includes agent_state, global_state and action_mask, all of which are a one-dimensional Tensor type array
Action Space¶
Basically no transformation, still a discrete action space of size N
Reward Space¶
Transformation content: Set fake_reward, so that the agent can get rewards after making some actions. We set the fake_reward of each step to ‘killed enemy’s blood - lost one’s blood’, and destroying an enemy will reward 20 points, Get 200 points for a global victory
Transformation result: a one-dimensional Tensor that contains only one float32 type of data
Other¶
Turn on
special_global_stateand the returned global_state is the information spliced into each global information + each agent’s special information. If it is not turned on, only the global information will be returnedTurn on
special_global_stateand turn ondeath_mask, if an agent dies, the returned global_state only contains its own ID information, and all other information is maskedThe
inforeturned by the environmentstepmethod must contain theeval_episode_returnkey-value pair, which represents the evaluation index of the entire episode, and is the cumulative sum of the fake_reward of the entire episode in SMACThe final
rewardreturned by the environmentstepmethod is victory or not
Other¶
Lazy Initialization¶
In order to facilitate parallel operations such as environment vectorization, environment instances generally implement lazy initialization, that is, the __init__method does not initialize the real original environment instance, but only sets relevant parameters and configuration values. The concrete original environment instance is initialized when the resetmethod is used.
Random Seed¶
There are two parts of random seeds in the environment that need to be set, one is the random seed of the original environment, and the other is the random seed of the random library used by various environment transformations (such as
random,np.random)For the environment caller, just set these two seeds through the
seedmethod of the environment, and do not need to care about the specific implementation detailsConcrete implementation inside the environment: For the seed of the original environment, set before calling the
resetmethod of the environment, before the concreteresetConcrete implementation inside the environment: For random library seeds, set the value directly in the
seedmethod of the environment
The Difference between Training and Testing Environments¶
The training environment uses a dynamic random seed, that is, the random seed of each episode is different, and is generated by a random number generator, but the seed of this random number generator is fixed by the
seedmethod of the environment ;The test environment uses a static random seed, that is, the random seed of each episode is the same, specified by theseedmethod.
Store Video¶
Use the method provided by `<https://github.com/opendilab/DI-engine/blob/main/dizoo/smac/utils/eval.py>`_ to store the video and play the store in the StarCraft 2 game ‘s video.
from typing import Union, Optional, List, Any, Callable, Tuple
import pickle
import torch
from functools import partial
from ding.config import compile_config, read_config
from ding.envs import get_vec_env_setting
from ding.policy import create_policy
from ding.utils import set_pkg_seed
def eval(
input_cfg: Union[str, Tuple[dict, dict]],
seed: int = 0,
env_setting: Optional[List[Any]] = None,
model: Optional[torch.nn.Module] = None,
state_dict: Optional[dict] = None,
) -> float:
if isinstance(input_cfg, str):
cfg, create_cfg = read_config(input_cfg)
else:
cfg, create_cfg = input_cfg
create_cfg.policy.type += '_command'
cfg = compile_config(cfg, auto=True, create_cfg=create_cfg)
env_fn, _, evaluator_env_cfg = get_vec_env_setting(cfg.env)
env = env_fn(evaluator_env_cfg[0])
env.seed(seed, dynamic_seed=False)
set_pkg_seed(seed, use_cuda=cfg.policy.cuda)
policy = create_policy(cfg.policy, model=model, enable_field=['eval']).eval_mode
if state_dict is None:
state_dict = torch.load(cfg.learner.load_path, map_location='cpu')
policy.load_state_dict(state_dict)
obs = env.reset()
episode_return = 0.
while True:
policy_output = policy.forward({0:obs})
action = policy_output[0]['action']
print(action)
timestep = env.step(action)
episode_return += timestep.reward
obs = timestep.obs
if timestep.done:
print(timestep.info)
break
env.save_replay(replay_dir='.', prefix=env._map_name)
print('Eval is over! The performance of your RL policy is {}'.format(episode_return))
if __name__ == "__main__":
path = '' #model path
cfg = '' config path
state_dict = torch.load(path, map_location='cpu')
eval(cfg, seed=0, state_dict=state_dict)
DI-zoo Runnable Code Example¶
The full training configuration file is at github
link
Inside, for specific configuration files, such as smac_3s5z_mappo_config.py, use the following demo to run:
import sys
from copy import deepcopy
from ding.entry import serial_pipeline_onpolicy
from easydict import EasyDict
agent_num = 8
collector_env_num = 8
evaluator_env_num = 8
special_global_state = True
main_config = dict(
exp_name='smac_3s5z_mappo',
env=dict(
map_name='3s5z',
difficulty=7,
reward_only_positive=True,
mirror_opponent=False,
agent_num=agent_num,
collector_env_num=collector_env_num,
evaluator_env_num=evaluator_env_num,
n_evaluator_episode=16,
stop_value=0.99,
death_mask=False,
special_global_state=special_global_state,
# save_replay_episodes = 1,
manager=dict(
shared_memory=False,
reset_timeout=6000,
),
),
policy=dict(
cuda=True,
multi_agent=True,
continuous=False,
model=dict(
# (int) agent_num: The number of the agent.
# For SMAC 3s5z, agent_num=8; for 2c_vs_64zg, agent_num=2.
agent_num=agent_num,
# (int) obs_shape: The shapeension of observation of each agent.
# For 3s5z, obs_shape=150; for 2c_vs_64zg, agent_num=404.
# (int) global_obs_shape: The shapeension of global observation.
# For 3s5z, obs_shape=216; for 2c_vs_64zg, agent_num=342.
agent_obs_shape=150,
#global_obs_shape=216,
global_obs_shape=295,
# (int) action_shape: The number of action which each agent can take.
# action_shape= the number of common action (6) + the number of enemies.
# For 3s5z, obs_shape=14 (6+8); for 2c_vs_64zg, agent_num=70 (6+64).
action_shape=14,
# (List[int]) The size of hidden layer
# hidden_size_list=[64],
),
# used in state_num of hidden_state
learn=dict(
# (bool) Whether to use multi gpu
multi_gpu=False,
epoch_per_collect=5,
batch_size=3200,
learning_rate=5e-4,
# =================================================== =============
# The following configs are algorithm-specific
# =================================================== =============
# (float) The loss weight of value network, policy network weight is set to 1
value_weight=0.5,
# (float) The loss weight of entropy regularization, policy network weight is set to 1
entropy_weight=0.01,
# (float) PPO clip ratio, defaults to 0.2
clip_ratio=0.2,
# (bool) Whether to use advantage norm in a whole training batch
adv_norm=False,
value_norm=True,
ppo_param_init=True,
grad_clip_type='clip_norm',
grad_clip_value=10,
ignore_done=False,
),
on_policy=True,
collect=dict(env_num=collector_env_num, n_sample=3200),
eval=dict(env_num=evaluator_env_num, evaluator=dict(eval_freq=50, )),
),
)
main_config = EasyDict(main_config)
create_config = dict(
env=dict(
type='smac',
import_names=['dizoo.smac.envs.smac_env'],
),
env_manager=dict(type='base'),
policy=dict(type='ppo'),
)
create_config = EasyDict(create_config)
if __name__ == "__main__":
serial_pipeline_onpolicy([main_config, create_config], seed=0)
Note: For On policy algorithm, use serial_pipeline_onpolicy to enter, for Off policy algorithm, use serial_pipeline to enter
Benchmark Algorithm Performance¶
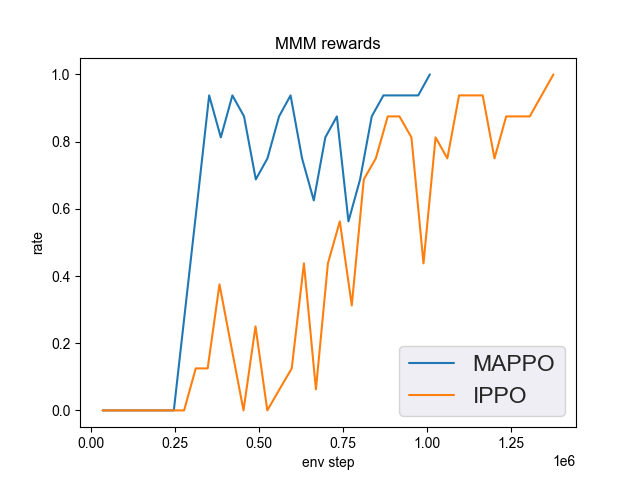
MMM (1 win rate under 2M env step is considered better performance)
MMM + MAPPO
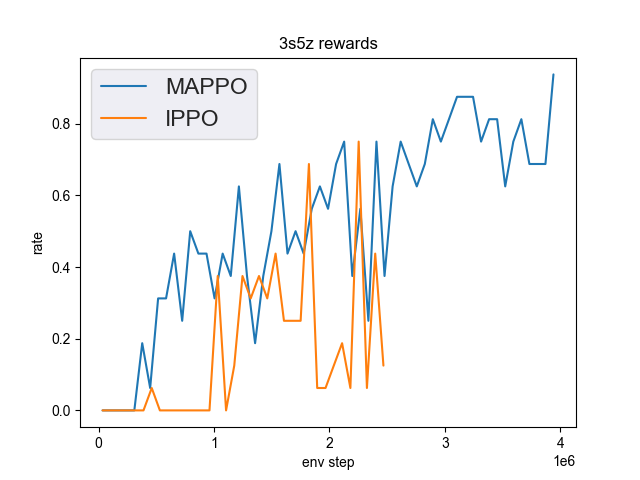
3s5z (1 win rate under 3M env step is considered better performance)
3s5z + MAPPO
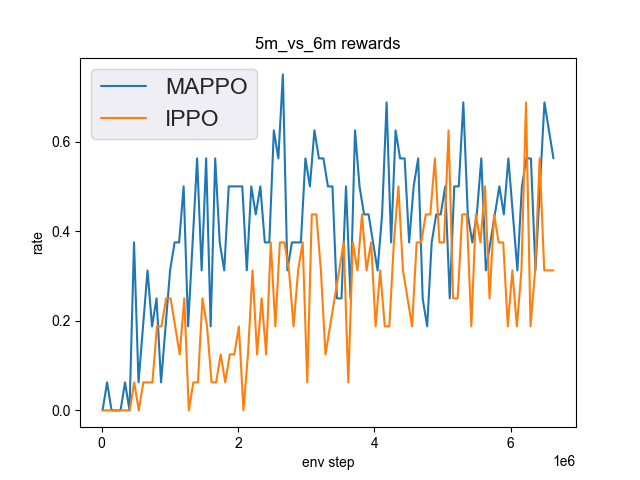
5m_vs_6m (0.75 win rate under 5M env step is considered as good performance)
5m_vs_6m + MAPPO
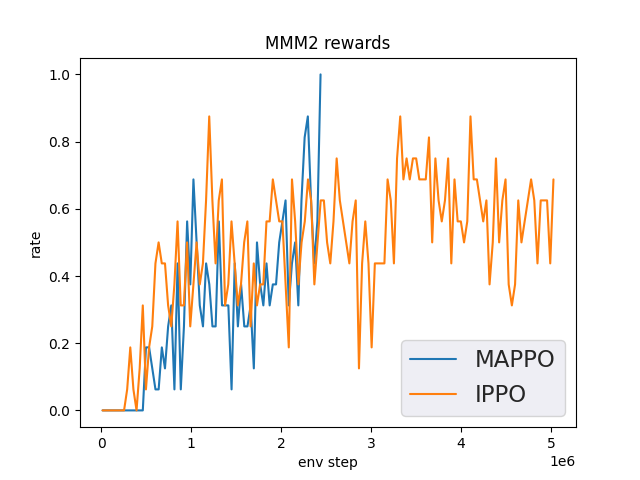
MMM2 (1 win rate under 5M env step is considered better performance)
MMM2 + MAPPO