C51¶
概述¶
C51 最初是在 A Distributional Perspective on Reinforcement Learning 中提出的,与以往的研究不同,C51 评估了 q 值的完整分布,而不仅仅是期望值。作者设计了一个分布式 Bellman 算子,它保留了值分布中的多峰性,被认为能够实现更稳定的学习,并减轻从非稳态策略学习的负面影响。
核心要点¶
C51 是一种 无模型(model-free) 和 基于值(value-based) 的强化学习算法。
C51 仅 支持离散动作空间 。
C51 是一种 异策略(off-policy) 算法。
通常, C51 使用 eps-greedy 或 多项式采样 进行探索。
C51 可以与循环神经网络 (RNN) 结合使用。
伪代码¶

备注
C51 使用离散分布来建模值分布,其支持集合为N个原子: \(z_i = V_\min + i * delta, i = 0,1,...,N-1\) 和 \(delta = (V_\max - V_\min) / N\) 。每个原子 \(z_i\) 都有一个参数化的概率 \(p_i\) 。C51 的贝尔曼更新将 \(r + \gamma * z_j^{\left(t+1\right)}\) 的分布投影到分布 \(z_i^t\) 上。
关键方程或关键框图¶
C51 的贝尔曼方程的目标是通过将返回分布 \(r + \gamma * z_j\) 投影到当前分布 \(z_i\) 上来得到的. 给定一个采样出来的状态转移 \((x, a, r, x')\),我们为每个原子 \(z_j\) 计算贝尔曼更新 \(Tˆz_j := r + \gamma z_j\) ,然后将其概率 \(p_{j}(x', \pi(x'))\) 分配给其相邻的原子 \(p_{i}(x, \pi(x))\):
扩展¶
- C51 可以和以下模块结合:
优先经验回放 (Prioritized Experience Replay)
多步时序差分 (TD) 损失
双目标网络 (Double Target Network)
Dueling head
循环神经网络 (RNN)
实现¶
小技巧
我们的 C51 基准结果使用了与 DQN 相同的超参数,(除 n_atom 这个 C51 特有的参数以外),这也是配置 C51 的通用方法。
C51 的默认配置如下:
C51 使用的网络接口定义如下:
基准测试¶
environment |
best mean reward |
evaluation results |
config link |
comparison |
|---|---|---|---|---|
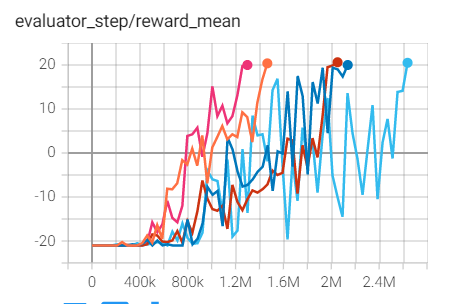
Pong
(PongNoFrameskip-v4)
|
20.6 |
|
Tianshou(20)
|
|
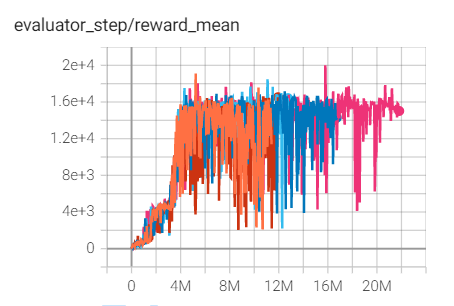
Qbert
(QbertNoFrameskip-v4)
|
20006 |
|
Tianshou(16245)
|
|
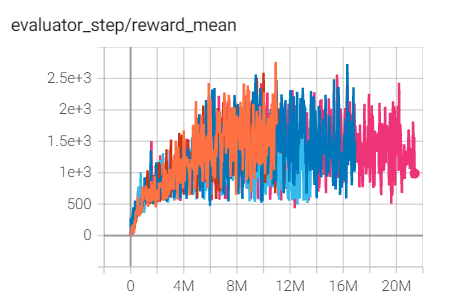
SpaceInvaders
(SpaceInvadersNoFrame skip-v4)
|
2766 |
|
Tianshou(988.5)
|
P.S.:
上述结果是在五个不同的随机种子(0、1、2、3、4)上运行相同配置的实验得出的。
对于像 DQN 这样的离散动作空间算法,通常使用 Atari 环境集进行测试(包括子环境 Pong ),而 Atari 环境通常通过训练10M个环境步骤的最高平均奖励来评估。关于 Atari 的更多细节,请参考 Atari Env Tutorial 。