EDAC¶
综述¶
离线强化学习(offline-RL)是一个新出现的研究领域,旨在使用大量先前收集的数据集来学习行为,而无需进一步与环境进行交互。 它有可能解决许多实际决策问题,尤其是那些数据收集较为昂贵的应用问题(例如,在机器人,药物发现,对话生成,推荐系统中)或那些具有危险性的应用问题(例如,医疗保健,自动驾驶或教育)。 此外,对于一些环境,在线收集的数据量远远低于离线数据集。离线强化学习的范式有望解决将强化学习算法从实验室环境带到现实世界的关键挑战。
然而,在离线设置中直接使用现有的基于价值的 off-policy RL 算法通常会导致性能不佳,这是由于从分布外动作(out-of-distribution actions)引导和过度拟合等问题。 因此,许多约束技术(例如策略约束;保守估计;不确定性估计)被添加到基本在线 RL 算法中。 基于不确定性的离线强化学习与多 样化 Q-Ensemble(EDAC),首次提出于 Uncertainty-Based Offline Reinforcement Learning with Diversified Q-Ensemble, 是其中之一,它通过添加更多 Critic Network 来惩罚分布外(OOD)操作。
快速了解¶
EDAC 是一种离线不确定性估计 RL 算法。
EDAC 可以在 SAC RL 及相关衍生算法之上用不到20行代码实现。
EDAC 支持连续动作空间。
重要公式/重要图示¶
EDAC 表明,通过增加 Critic 的数量,可以通过截断 Q 学习(clipped Q-learning) \(min_{j=1,2}Q(s,a)\) 来惩罚 OOD 操作。 因此,EDAC 可以通过在标准 SAC RL 算法上集成 Q 网络并添加惩罚项来惩罚 OOD 操作来实现。
通常,对于 EDAC,惩罚项如下:

通过添加上述惩罚项,该算法可以最小化实现更高计算效率的必要 Critic 数量,同时保持良好的性能。该项计算数据集状态操作的 Q 值梯度的内积。
EDAC 通过增加 SAC 算法中 Q 网络的数量来显示截断 Q 学习的重要性。通过计算 clip 惩罚和 OOD 操作和数据集操作的标准偏差,论文显示为什么算法通过增加 Q 网络的数量会表现得更好,如下图所示:

在下图中,论文显示了 OOD 操作的 Q 值梯度,其中红色向量表示 OOD 操作下的方向。我们发现,如果 OOD 操作的 Q 值的方差较小,则在梯度下降过程中将获得较小的惩罚 。这进一步解释了为什么增加 Critic 数量可以惩罚 OOD 操作,并且也指示了论文后期改进的方向。

尽管增加 Q 网络的数量可以提高性能,但过多的 Q 网络将成为负担。因此,EDAC 添加了惩罚项以减少 Critic 数量。 使用一阶泰勒近似,沿 w 的 OOD 操作处 Q 值的样本方差可以表示如下:

为了有效地增加邻近原始数据集分布 OOD 操作的 Q 值方差,EDAC 最大化以下方程:

有几种方法可以计算最小特征值,例如幂方法或 QR 算法。然而,这些迭代方法需要构建巨大的计算图,这使得使用反向传播优化特征值效率低下。相反,我们的目标是最大化所有特征值 的总和,这等价于最大化总方差。因此,上述方程等同于最小化第一幅图的方程。
伪代码¶
伪代码显示在算法1中,与传统的 Actor-Critic 算法(例如 SAC)的区别以蓝色显示。

实现¶
EDAC Policy 的默认配置定义如下:
Benchmark¶
environment |
best mean reward |
evaluation results |
config link |
comparison |
|---|---|---|---|---|
HalfCheetah (Medium Expert) |
92.5 \(\pm\) 9.9 |
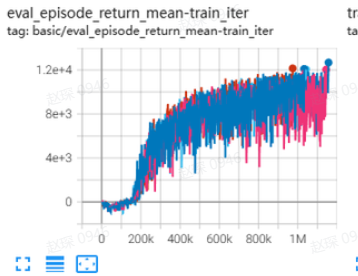
|
EDAC Repo (106.3 \(\pm\) 1.9) |
|
Hopper (Medium Expert) |
110.8 \(\pm\) 1.3 |
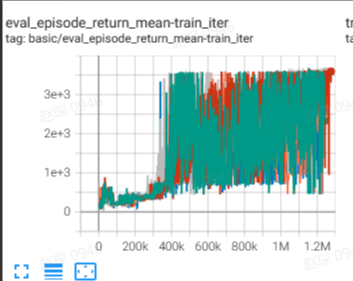
|
EDAC Repo (110.7 \(\pm\) 0.1) |
Specifically for each dataset, our implementation results are as follows:
environment |
medium expert |
medium |
|---|---|---|
HalfCheetah |
92.5 \(\pm\) 2.8 |
59.9 \(\pm\) 2.8 |
Hopper |
110.8 \(\pm\) 1.3 |
100.5 \(\pm\) 1.6 |
P.S.: 1. 上述结果是通过在四个不同的随机种子(0、42、88、123、16)上运行相同的配置获得的。 2. 上述基准测试是针对 HalfCheetah-v2,Hopper-v2。 3. 上述比较结果是通过论文 Uncertainty-Based Offline Reinforcement Learning with Diversified Q-Ensemble。 完整表格如下所示:

上述 Tensorboard 结果给出了未归一化的结果
参考文献¶
Kumar, Aviral, et al. “Conservative q-learning for offline reinforcement learning.” arXiv preprint arXiv:2006.04779 (2020).
Chenjia Bai, et al. “Pessimistic Bootstrapping for Uncertainty-Driven Offline Reinforcement Learning.”