IQN¶
概述¶
IQN 是在 Implicit Quantile Networks for Distributional Reinforcement Learning 被提出的。 Distributional RL 的研究目标是通过建模值函数的概率分布,更全面地描述不同动作的预期奖励分布。 IQN (Implicit Quantile Network)和 QRDQN (Quantile Regression DQN) 之间的关键区别在于, IQN 引入了隐式量化网络(Implicit Quantile Network),它是一个确定性参数化函数,通过训练将来自基本分布(例如在U([0, 1])上的 tau )的样本重新参数化为目标分布的相应分位数值,而 QRDQN 直接学习了一组预定义的固定分位数。
要点摘要:¶
IQN 是一种 无模型(model-free) 和 基于值(value-based) 的强化学习算法。
IQN 仅支持 离散动作空间 。
IQN 是一种 异策略(off-policy) 算法。
通常情况下, IQN 使用 eps-greedy 或 多项式采样(multinomial sample) 进行探索。
IQN 可以与循环神经网络 (RNN) 结合使用。
关键方程¶
在隐式量化网络中,首先通过以下方式将采样的分位数tau编码为嵌入向量:
\[\phi_{j}(\tau):=\operatorname{ReLU}\left(\sum_{i=0}^{n-1} \cos (\pi i \tau) w_{i j}+b_{j}\right)\]
然后,分位数嵌入(quantile embedding)与环境观测的嵌入(embedding)进行逐元素相乘,并通过后续的全连接层将得到的乘积向量映射到相应的分位数值。
关键图¶
以下是DQN、C51、QRDQN和IQN之间的比较:
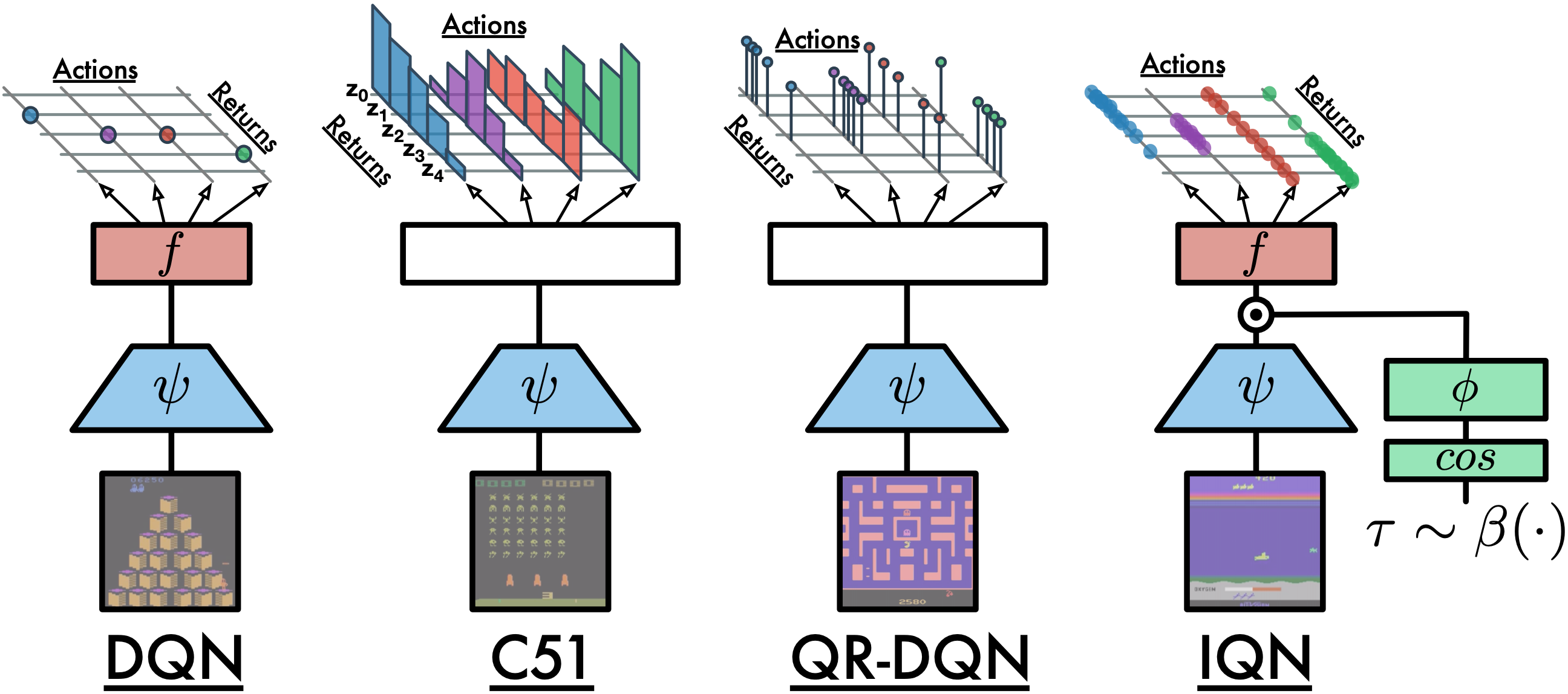
扩展¶
- IQN 可以与以下技术相结合使用:
优先经验回放 (Prioritized Experience Replay)
小技巧
是否优先级经验回放 (PER) 能够提升 IQN 的性能取决于任务和训练策略。
多步时序差分 (TD) 损失
双目标网络 (Double Target Network)
循环神经网络 (RNN)
实现¶
小技巧
我们的IQN基准结果使用与DQN相同的超参数,除了IQN的独有超参数, the number of quantiles, 它经验性地设置为32。不推荐将分位数的数量设置为大于64,因为这会带来较小的收益,并且会增加更多的前向传递延迟。
IQN算法的默认配置如下所示:
IQN算法使用的网络接口定义如下:
IQN算法中使用的贝尔曼更新(Bellman update)在 iqn_nstep_td_error 函数中定义,我们可以在 ding/rl_utils/td.py 文件中找到它。
基准¶
environment |
best mean reward |
evaluation results |
config link |
comparison |
|---|---|---|---|---|
Pong (PongNoFrameskip-v4) |
20 |
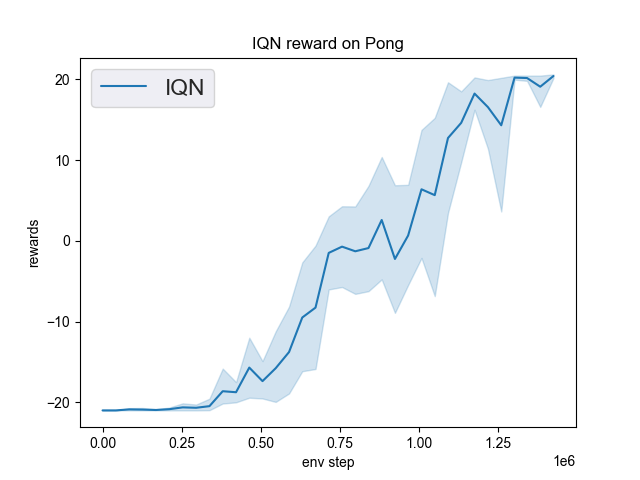
|
Tianshou(20) |
|
Qbert (QbertNoFrameskip-v4) |
16331 |
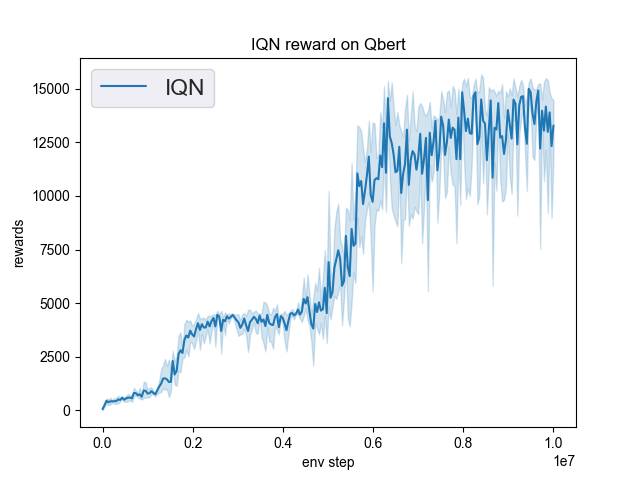
|
Tianshou(15520) |
|
SpaceInvaders (SpaceInvadersNoFrame skip-v4) |
1493 |
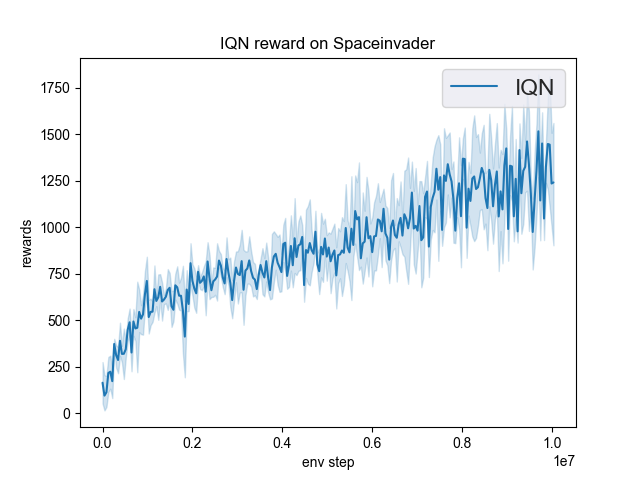
|
Tianshou(1370) |
P.S.: 1. 上述结果是通过在五个不同的随机种子 (0, 1, 2, 3, 4)上运行相同的配置获得的。
参考文献¶
(IQN) Will Dabney, Georg Ostrovski, David Silver, Rémi Munos: “Implicit Quantile Networks for Distributional Reinforcement Learning”, 2018; arXiv:1806.06923. https://arxiv.org/pdf/1806.06923