PPG¶
概述¶
PPG 是在 Phasic Policy Gradient 中提出的。在以前的方法中,人们需要选择表示策略和价值函数是否需要分开训练还是共享全局信息。分开训练可以避免目标之间的干扰,而使用共享全局信息可以实现有用特征的共享。PPG 能够兼顾两者的优点,通过将优化分为两个阶段,一个用于推进训练,另一个用于提取特征。
核心要点¶
PPG 是一种无模型、基于策略的强化学习算法。
PP 支持离散动作空间和连续动作空间。
PPG 支持离策略模式和在策略模式。
PPG 中有两个价值网络。
在 DI-engine 的实现中,我们对离策略PPG使用了两个缓冲区,它们仅在数据使用次数约束(数据 “max_use” )上有所不同。
重要图示¶
PPG 利用分开的策略和价值网络来减少目标之间的干扰。策略网络包括一个辅助价值头部网络,用于将价值知识提取到策略网络中,具体的网络结构如下所示:

重要公式¶
PPG 的优化分为两个阶段,策略阶段和辅助阶段。在策略阶段,策略网络和价值网络的更新方式类似于 PPO。在辅助阶段,使用联合损失将价值知识提取到策略网络中:
联合损失函数优化辅助目标(蒸馏),同时通过 KL 散度限制(即第二项)保留原始策略。辅助损失定义如下:
伪代码¶
on-policy 训练流程¶
以下流程图展示了 PPG 如何在策略阶段和辅助阶段之间进行交替

备注
在辅助阶段,PPG 还会对值网络进行额外的训练。
off-policy 训练流程¶
DI-engine 实现了采用两个不同数据使用次数约束(”max_use”)缓冲区的 PPG。其中,策略缓冲区提供策略阶段的数据,而值缓冲区提供辅助阶段的数据。整个训练过程类似于 off-policy PPO,但会以固定频率执行额外的辅助阶段。
扩展¶
PPG 可以与以下方法结合使用:
GAE 或其他优势估计方法
多个具有不同的最大数据使用次数限制的回访缓存
在 procgen 环境中,PPO(或 PPG)+ UCB-DrAC + PLR 是最好的方法之一。
实现¶
默认配置如下所示:
PPG 使用的网络定义如下:
Benchmark¶
environment |
best mean reward |
evaluation results |
config link |
comparison |
|---|---|---|---|---|
Pong
(PongNoFrameskip-v4)
|
20 |
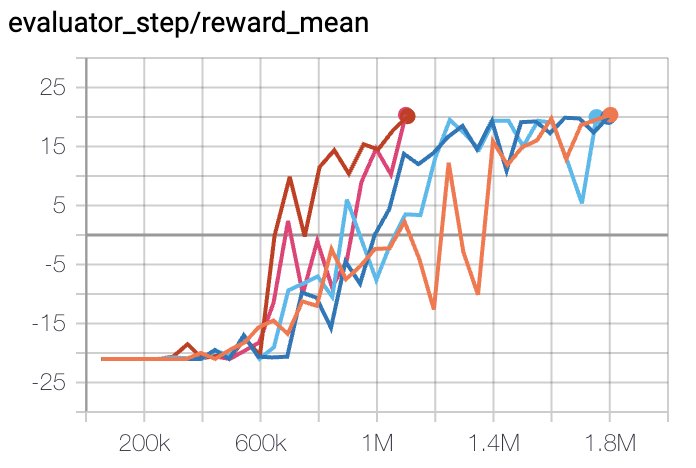
|
DI-engine PPO off-policy(20)
|
|
Qbert
(QbertNoFrameskip-v4)
|
17775 |
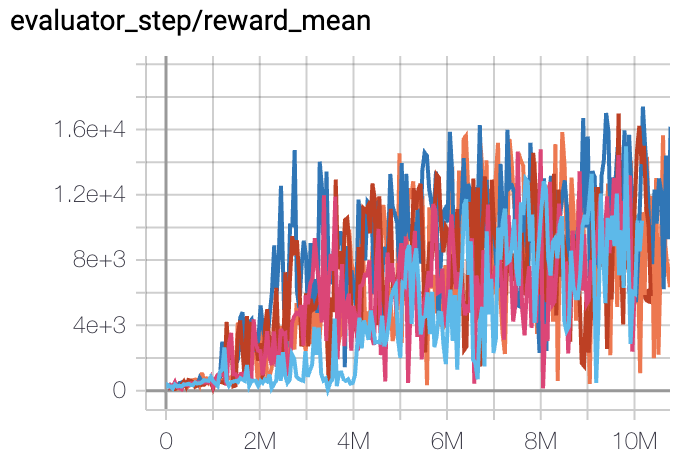
|
DI-engine PPO off-policy(16400)
|
|
SpaceInvaders
(SpaceInvadersNoFrame skip-v4)
|
1213 |
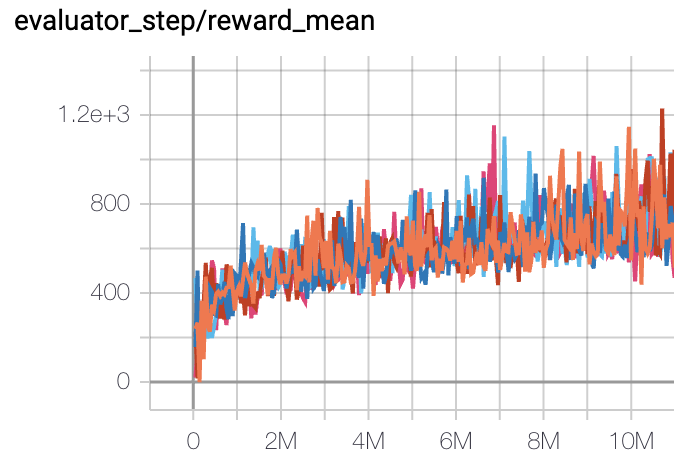
|
DI-engine PPO off-policy(1200)
|
引用¶
Karl Cobbe, Jacob Hilton, Oleg Klimov, John Schulman: “Phasic Policy Gradient”, 2020; arXiv:2009.04416.