CartPole¶
概述¶
倒立摆问题是强化学习中的经典控制问题。CartPole 是倒立摆问题中的一个离散控制任务。在游戏中有一个小车,上有竖着一根杆子。小车在一个光滑无摩擦的轨道上左右滑行,目的是使杆子保持竖直。如下图所示。

安装¶
安装方法¶
CartPole 环境内置在 gym 中,直接安装 gym 即可。其环境 id 是CartPole-v0 。
pip install gym
验证安装¶
在 Python 命令行中运行如下命令验证安装成功。
import gym
env = gym.make('CartPole-v0')
obs = env.reset()
print(obs)
环境介绍¶
动作空间¶
CartPole 的动作空间属于离散动作空间,有 2 个离散动作,分别是左移和右移。
左移: 0 表示让 agent 向左移动。右移: 1 表示让 agent 向右移动。
使用 gym 环境空间定义则可表示为:
action_space = spaces.Discrete(2)
状态空间¶
CartPole 的状态空间有 4 个元素,分别是:
Cart Position:小车的位置,范围是[-4.8, 4.8]。Cart Velocity:小车的速度,范围是[-inf, inf]。Pole Angle:杆的角度,范围是[-24 deg, 24 deg]。Pole Angular Velocity:杆的角速度,范围是[-inf, inf]。
奖励空间¶
每一步操作,都将获得值为 1 的奖励,直到 episode 终止(终止状态也将获得值为 1 的奖励)。
终止条件¶
CartPole 环境每个 episode 的终止条件是遇到以下任何一种情况:
杆偏移的角度超过 12 度。
小车出界,通常把边界距离设置为 2.4。
达到 episode 的最大 step,默认为 200。
CartPole 任务在什么情况下视为胜利¶
当100次试验的平均 episode 奖励达到 195 以上时,视作游戏胜利。
DI-zoo 可运行代码示例¶
下面提供一个完整的 CartPole 环境 config,采用 DQN 算法作为 policy。请在DI-engine/ding/example 目录下运行dqn_nstep.py 文件,具体实现如下。
import gym
from ditk import logging
from ding.model import DQN
from ding.policy import DQNPolicy
from ding.envs import DingEnvWrapper, BaseEnvManagerV2
from ding.data import DequeBuffer
from ding.config import compile_config
from ding.framework import task
from ding.framework.context import OnlineRLContext
from ding.framework.middleware import OffPolicyLearner, StepCollector, interaction_evaluator, data_pusher, \
eps_greedy_handler, CkptSaver, nstep_reward_enhancer, final_ctx_saver
from ding.utils import set_pkg_seed
from dizoo.classic_control.cartpole.config.cartpole_dqn_config import main_config, create_config
def main():
logging.getLogger().setLevel(logging.INFO)
main_config.exp_name = 'cartpole_dqn_nstep'
main_config.policy.nstep = 3
cfg = compile_config(main_config, create_cfg=create_config, auto=True)
with task.start(async_mode=False, ctx=OnlineRLContext()):
collector_env = BaseEnvManagerV2(
env_fn=[lambda: DingEnvWrapper(gym.make("CartPole-v0")) for _ in range(cfg.env.collector_env_num)],
cfg=cfg.env.manager
)
evaluator_env = BaseEnvManagerV2(
env_fn=[lambda: DingEnvWrapper(gym.make("CartPole-v0")) for _ in range(cfg.env.evaluator_env_num)],
cfg=cfg.env.manager
)
set_pkg_seed(cfg.seed, use_cuda=cfg.policy.cuda)
model = DQN(**cfg.policy.model)
buffer_ = DequeBuffer(size=cfg.policy.other.replay_buffer.replay_buffer_size)
policy = DQNPolicy(cfg.policy, model=model)
task.use(interaction_evaluator(cfg, policy.eval_mode, evaluator_env))
task.use(eps_greedy_handler(cfg))
task.use(StepCollector(cfg, policy.collect_mode, collector_env))
task.use(nstep_reward_enhancer(cfg))
task.use(data_pusher(cfg, buffer_))
task.use(OffPolicyLearner(cfg, policy.learn_mode, buffer_))
task.use(CkptSaver(policy, cfg.exp_name, train_freq=100))
task.use(final_ctx_saver(cfg.exp_name))
task.run()
if __name__ == "__main__":
main()
实验结果¶
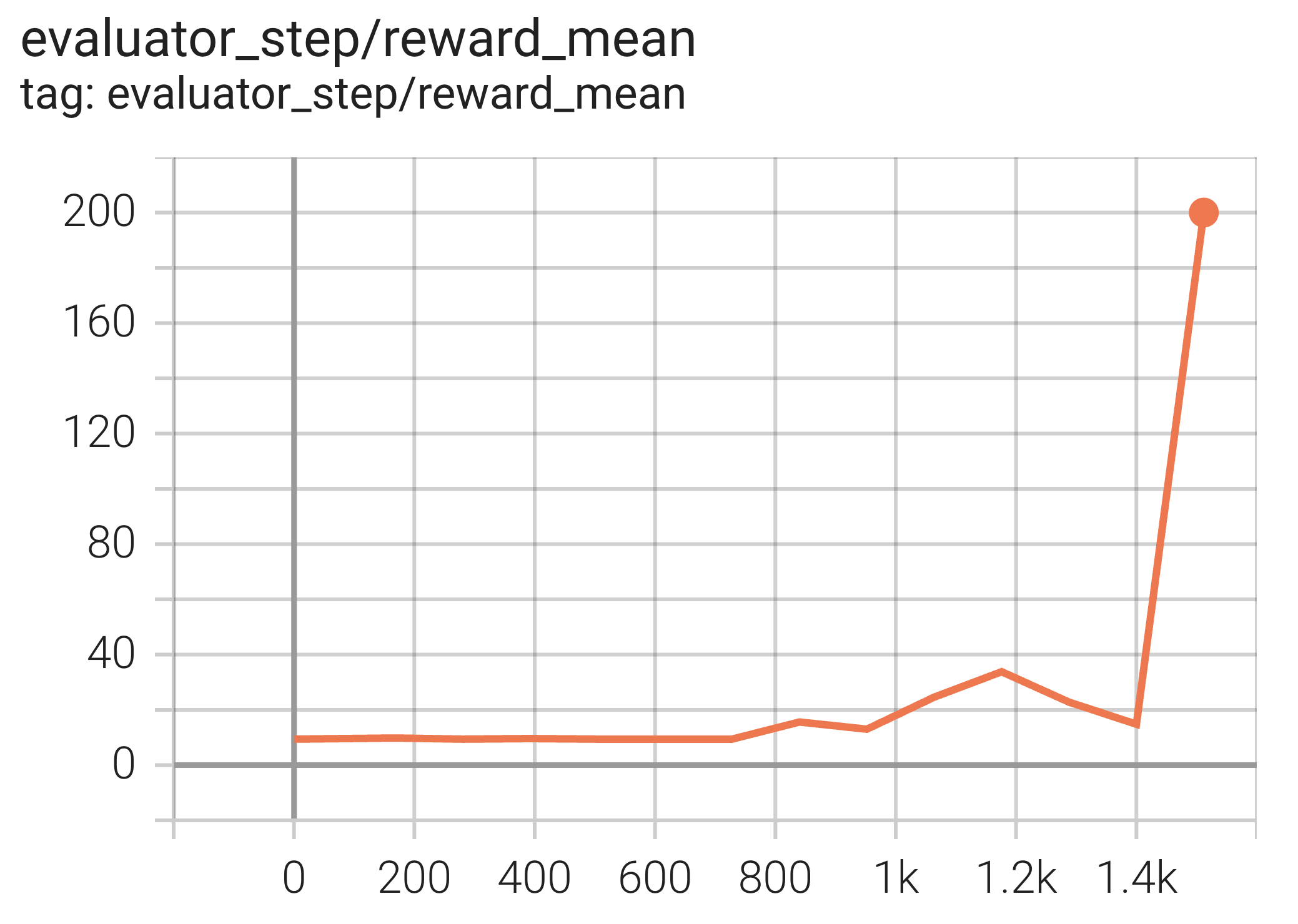
使用 DQN 算法的实验结果如下。横坐标是和环境交互的步数,即 env step ,纵坐标是epsiode reward mean 。
参考资料¶
CartPole 源码