Gym-Hybrid¶
概述¶
在 gym-hybrid 任务中, 智能体需要在一个正方形框内,从随机出发点启动,通过加速(Accelerate)、转向(Turn)或刹车(Break)等一系列控制操作,最终希望停留在绿色目标区域(一个有目标旗帜的圆)。如下图所示:
安装¶
安装方法¶
cd ./DI-engine/dizoo/gym_hybrid/envs/gym-hybrid
pip install -e .
验证安装¶
方法一: 运行如下命令, 如果能正常显示版本信息,即顺利安装完成。
pip show gym-hybrid
方法二: 运行如下 Python 程序,如果没有报错则证明安装成功。
import gym
import gym_hybrid
env = gym.make('Moving-v0')
obs = env.reset()
print(obs)
环境介绍¶
动作空间¶
Gym-hybrid 的动作空间属于离散连续动作混合空间,有3 个离散动作:Accelerate ,Turn ,Break ,其中动作 Accelerate ,Turn 需要给出对应的 1 维连续参数。
Accelerate (Acceleration value): 表示让智能体以acceleration value的大小加速。Acceleration value的取值范围是[0,1]。数值类型为float32。Turn (Rotation value): 表示让智能体朝rotation value的方向转身。Rotation value的取值范围是[-1,1]。数值类型为float32。Break (): 表示停止。
使用 gym 环境空间定义则可表示为:
from gym import spaces
action_space = spaces.Tuple((spaces.Discrete(3),
spaces.Box(low=0, high=1, shape=(1,)),
spaces.Box(low=-1, high=1, shape=(1,))))
状态空间¶
Gym-hybrid 的状态空间是一个有 10 个元素的数组,描述了当前智能体的状态,包含智能体当前的坐标,速度,朝向角度的正余弦值,目标的坐标,距离目标的距离,是否达到目标,当前相对步数。
state = [
agent.x,
agent.y,
agent.speed,
np.cos(agent.theta),
np.sin(agent.theta),
target.x,
target.y,
distance,
0 if distance > target_radius else 1,
current_step / max_step
]
奖励空间¶
每一步的奖励设置为,智能体上一个 step 执行动作后到目标的距离,减去当前 step 执行动作后距离目标的距离,即dist_t-1 - dist_t 。另外,算法内置了一个惩罚项penalty 来激励智能体更快的
达到目标。当 episode 结束时,如果智能体在目标区域停下来,就会获得额外的 reward,值为 1;如果智能体出界或是超过 episode 最大步数,则不会获得额外奖励。奖励的伪代码实现如下:
reward = last_distance - distance - penalty + (1 if goal else 0)
终止条件¶
遇到以下任何一种情况,则环境会该认为当前 episode 终止:
智能体成功进入目标区域
智能体出界,触及边缘
达到 episode 的最大上限步数(默认设置为200)
内置环境¶
内置有两个环境,"Moving-v0" 和"Sliding-v0" 。前者不考虑惯性守恒,而后者考虑(所以更切合实际)。两个环境在状态空间、动作空间、奖励空间上都保持一致。
DI-zoo 可运行代码示例¶
完整的训练配置文件在 github link 内,对于具体的配置文件,例如 gym_hybrid_ddpg_config.py ,使用如下命令即可运行:
python3 ./DI-engine/dizoo/gym_hybrid/config/gym_hybrid_ddpg_config.py
基准算法性能¶
Moving-v0(10M env step 后停止,平均奖励大于等于 1.8 视为表现较好的智能体)
Moving-v0
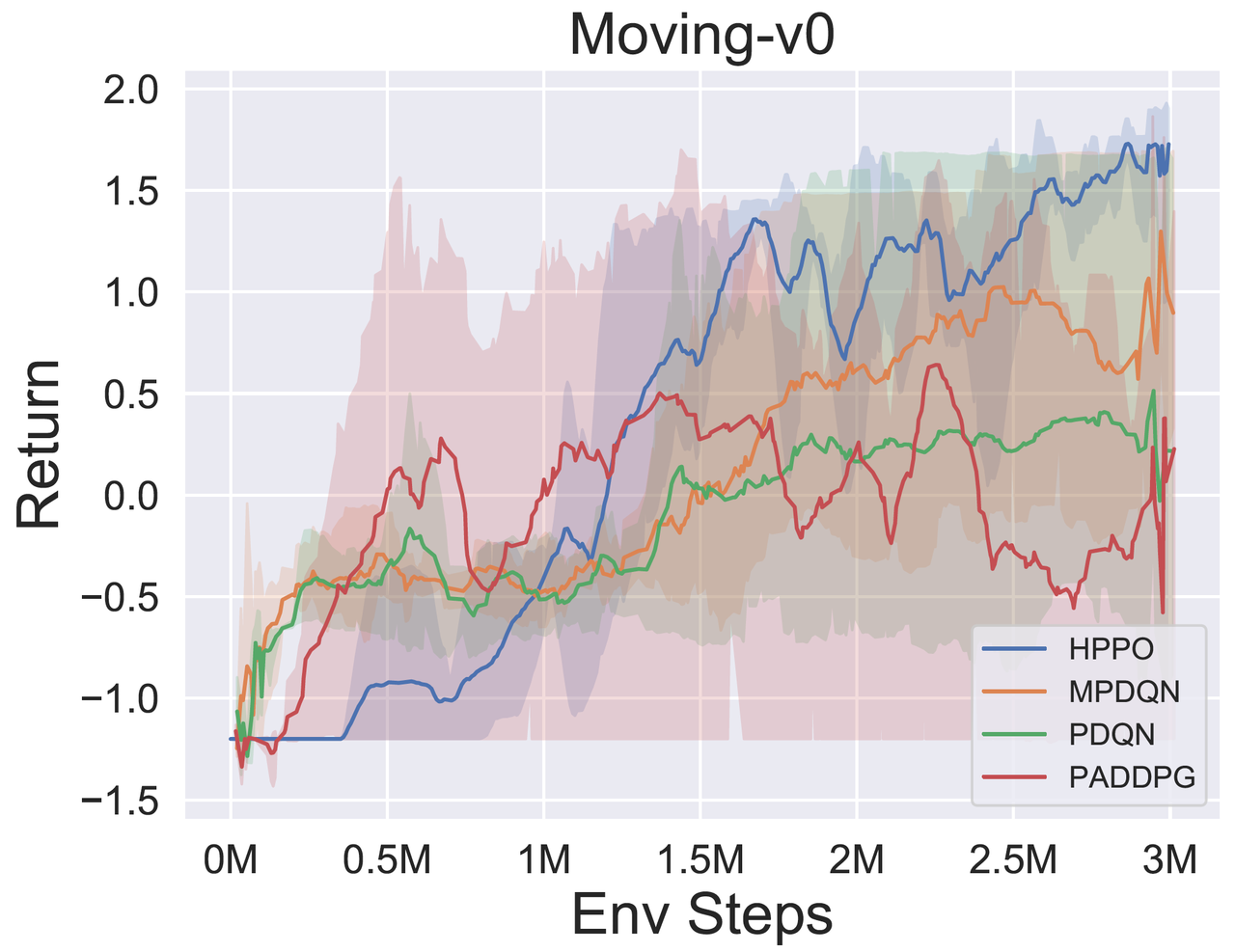
图1:HPPO 和其他混合动作空间算法在 Moving-v0 上的训练曲线图。实线表示各个算法在5个种子上的测试局对应 return 的平均值,阴影部分表示5个种子上的标准差,在每个种子的每个测试点上我们一共评估8局。横坐标为训练时与环境交互的步数。return>=1.5 的轨迹视为一次成功的移动。关于对比算法的详细信息,可以参考 知乎博客