Image Classification¶
概述¶
ImageNet 是一个按照 WordNet 层次结构(目前只有名词)组织的图像数据库,其中层次结构的每个节点都由成百上千的图像来描绘。 其在推进计算机视觉和深度学习研究方面发挥了重要作用。 该数据集已手动注释了 1400 多万张图像,以指出图片中的对象,并在至少 100 万张图像中提供了边框。 自2010 年以来,ImageNet 项目举办了一年一度的竞赛,即 ImageNet 大规模视觉识别挑战赛(ILSVRC),挑战赛使用 1000 个“整理”后的非重叠类, 通过竞赛来正确分类和检测对象和场景。 常用的数据集是其子数据集,也是 ISLVRC 2012(ImageNet Large Scale Visual Recognition Challenge) 比赛采用的数据集,共有 1000 个类别。其中:
训练集:1,281,167 张图片+标签
验证集:50,000 张图片+标签
测试集:100,000 张图片

下载及使用¶
下载方法¶
下载链接 ImageNet Datasets 将用于验证的 valid 数据集移动到相应的子文件夹,数据集预处理 shell 脚本。
加载数据集¶
下载完成后,可以通过在 Python 命令行中运行如下命令对数据集进行加载和测试:
from torch.utils.data import DataLoader
from dizoo.image_classification.data import ImageNetDataset, DistributedSampler
learn_data_path = '/mnt/lustre/share/images/train'
eval_data_path = '/mnt/lustre/share/images/val'
learn_dataset = ImageNetDataset(learn_data_path, is_training=True)
eval_dataset = ImageNetDataset(eval_data_path, is_training=False)
learn_dataloader = DataLoader(learn_dataset, batch_size=1, sampler=None, num_workers=2)
eval_dataloader = DataLoader(eval_dataset, batch_size=1, sampler=None, num_workers=2)
assert len(learn_dataloader) == 1281167
assert len(eval_dataloader) == 50000
数据集信息¶
数据集中图片信息主要包括两个部分,图片和标签。图片即 RGB 二维信息,标签是图片的类别。
图片信息¶
RGB 三通道图片,具体尺寸为(224, 224, 3),经过 Dataloader 后数据类型为torch.float32。
在 DI-engine 中,ImageNet 采用的数据转换方式有 Resize, Normalize, CenterCrop, Totensor等等:
Resize 将输入图像调整为给定的大小。
Normalize 使用均值和标准差对张量图像进行归一化。
CenterCrop 将在中心裁剪给定的图像。
ToTensor 将变量转换为张量。
标签信息¶
图片共有 1000个 标签,每个标签代表一种类别,在这里列出其前 5 种标签,
0: ‘tench, Tinca tinca’,
1: ‘goldfish, Carassius auratus’,
2: ‘great white shark, white shark, man-eater, man-eating shark, Carcharodon carcharias’,
3: ‘tiger shark, Galeocerdo cuvieri’,
4: ‘hammerhead, hammerhead shark’,
全部标签信息请查看 ImageNet Label
使用 DI-engine 完成 ImageNet 上的监督学习训练¶
将监督学习适配于强化学习框架 DI-engine 中。
基于强化学习框架中的 Policy 模块,负责图像分类网络的初始化、前向以及反向传播、优化器以及损失函数的定义。
设计适用于监督学习的图像分类度量方法 ImageClassificationMetric,其中包括 Top-K 计算等。
基于强化学习框架中的 Evaluator 模块,设计适用于监督学习的度量评价器 MetricSerialEvaluator。
基于强化学习框架中的 Learner 模块,负责训练网络的基本 pipeline。
基于强化学习框架中的 LearnerHook 模块,设计适用于监督学习的 log 信息记录的 ImageClsLogShowHook。
其他¶
为了加快训练,pytorch 中有两种常用的数据并行的方式,DataParallal(DP)以及DistributedDataParalle(DDP)。
DP以及DDP¶
DataParallal(DP)
DP 基于单机多卡,所有设备都负责计算和训练网络。 除此之外,device[0](并非GPU真实标号而是输入参数 device_ids 首位)还要负责整合梯度,更新参数。 其主要过程为各卡分别计算损失和梯度,将所有梯度整合到 device[0],device[0] 进行参数更新, 其他卡拉取 device[0] 的参数进行更新。但其实代码只需 1 行,汇总损失和梯度的操作以及参数同步都自动完成。
import torch.nn as nn
model = nn.DataParallel(model)
DistributedDataParallel(DDP)
DDP 主要用于单机多卡和多机多卡,其采用多进程控制多 gpu,并使用 ring allreduce 同步梯度。由于各个进程初始参数、更新梯度是相同的,采用同步后的梯度各自更新参数。 DDP 最佳推荐使用方法是每个进程一张卡,每张卡复制一份模型。 如果要确保 DDP 性能和单卡性能一致,需要保证在数据上,DDP 模式下的一个 epoch 和单卡下的一个 epoch 是等效的。 在多机多卡情况下分布式训练数据的读取是一个重要的问题,不同的卡读取到的数据应该是不同的。 DP 将训练数据切分到不同的卡,但对于多机来说,多机之间直接进行数据传输会严重影响效率。 于是利用 DistributedSampler 确保每一个子进程划分出一部分数据集,以避免不同进程之间数据重复。
训练集、测试集以及验证集的使用场景¶
训练集,用于训练模型参数。
验证集,用于调整分类器的参数,例如分类器中隐藏单元的数量。
测试集,仅用于评估分类器的性能以及泛化能力。
评估方法¶
对于 imagenet 图像分类任务,有一个重要的指标是`` Top-K `` 。 `` Top-K `` 准确率就是用来计算预测结果中概率最大的前K个结果包含正确标签的占比。 其计算方法如下
def accuracy(inputs: torch.Tensor, label: torch.Tensor, topk: Tuple = (1, 5)) -> dict:
"""Computes the accuracy over the k top predictions for the specified values of k"""
maxk = max(topk)
batch_size = label.size(0)
_, pred = inputs.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(label.reshape(1, -1).expand_as(pred))
return {'acc{}'.format(k): correct[:k].reshape(-1).float().sum(0) * 100. / batch_size for k in topk}
DI-zoo可运行代码示例¶
完整的训练配置文件在 github
link
内,对于具体的配置文件,例如imagenet_res18_config.py,使用如下的demo即可运行:
from typing import Union, Optional, Tuple, List
import time
import os
import torch
from tensorboardX import SummaryWriter
from torch.utils.data import DataLoader
from ding.worker import BaseLearner, LearnerHook, MetricSerialEvaluator, IMetric
from ding.config import read_config, compile_config
from ding.torch_utils import resnet18
from ding.utils import set_pkg_seed, get_rank, dist_init
from dizoo.image_classification.policy import ImageClassificationPolicy
from dizoo.image_classification.data import ImageNetDataset, DistributedSampler
from dizoo.image_classification.entry.imagenet_res18_config import imagenet_res18_config
class ImageClsLogShowHook(LearnerHook):
def __init__(self, *args, freq: int = 1, **kwargs) -> None:
super().__init__(*args, **kwargs)
self._freq = freq
def __call__(self, engine: 'BaseLearner') -> None: # noqa
# Only show log for rank 0 learner
if engine.rank != 0:
for k in engine.log_buffer:
engine.log_buffer[k].clear()
return
# For 'scalar' type variables: log_buffer -> tick_monitor -> monitor_time.step
for k, v in engine.log_buffer['scalar'].items():
setattr(engine.monitor, k, v)
engine.monitor.time.step()
iters = engine.last_iter.val
if iters % self._freq == 0:
# For 'scalar' type variables: tick_monitor -> var_dict -> text_logger & tb_logger
var_dict = {}
log_vars = engine.policy.monitor_vars()
attr = 'avg'
for k in log_vars:
k_attr = k + '_' + attr
var_dict[k_attr] = getattr(engine.monitor, attr)[k]()
# user-defined variable
var_dict['data_time_val'] = engine.data_time
epoch_info = engine.epoch_info
var_dict['epoch_val'] = epoch_info[0]
engine.logger.info(
'Epoch: {} [{:>4d}/{}]\t'
'Loss: {:>6.4f}\t'
'Data Time: {:.3f}\t'
'Forward Time: {:.3f}\t'
'Backward Time: {:.3f}\t'
'GradSync Time: {:.3f}\t'
'LR: {:.3e}'.format(
var_dict['epoch_val'], epoch_info[1], epoch_info[2], var_dict['total_loss_avg'],
var_dict['data_time_val'], var_dict['forward_time_avg'], var_dict['backward_time_avg'],
var_dict['sync_time_avg'], var_dict['cur_lr_avg']
)
)
for k, v in var_dict.items():
engine.tb_logger.add_scalar('{}/'.format(engine.instance_name) + k, v, iters)
# For 'histogram' type variables: log_buffer -> tb_var_dict -> tb_logger
tb_var_dict = {}
for k in engine.log_buffer['histogram']:
new_k = '{}/'.format(engine.instance_name) + k
tb_var_dict[new_k] = engine.log_buffer['histogram'][k]
for k, v in tb_var_dict.items():
engine.tb_logger.add_histogram(k, v, iters)
for k in engine.log_buffer:
engine.log_buffer[k].clear()
class ImageClassificationMetric(IMetric):
def __init__(self) -> None:
self.loss = torch.nn.CrossEntropyLoss()
@staticmethod
def accuracy(inputs: torch.Tensor, label: torch.Tensor, topk: Tuple = (1, 5)) -> dict:
"""Computes the accuracy over the k top predictions for the specified values of k"""
maxk = max(topk)
batch_size = label.size(0)
_, pred = inputs.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(label.reshape(1, -1).expand_as(pred))
return {'acc{}'.format(k): correct[:k].reshape(-1).float().sum(0) * 100. / batch_size for k in topk}
def eval(self, inputs: torch.Tensor, label: torch.Tensor) -> dict:
"""
Returns:
- eval_result (:obj:`dict`): {'loss': xxx, 'acc1': xxx, 'acc5': xxx}
"""
loss = self.loss(inputs, label)
output = self.accuracy(inputs, label)
output['loss'] = loss
for k in output:
output[k] = output[k].item()
return output
def reduce_mean(self, inputs: List[dict]) -> dict:
L = len(inputs)
output = {}
for k in inputs[0].keys():
output[k] = sum([t[k] for t in inputs]) / L
return output
def gt(self, metric1: dict, metric2: dict) -> bool:
if metric2 is None:
return True
for k in metric1:
if metric1[k] < metric2[k]:
return False
return True
def main(cfg: dict, seed: int) -> None:
cfg = compile_config(cfg, seed=seed, policy=ImageClassificationPolicy, evaluator=MetricSerialEvaluator)
if cfg.policy.learn.multi_gpu:
rank, world_size = dist_init()
else:
rank, world_size = 0, 1
# Random seed
set_pkg_seed(cfg.seed + rank, use_cuda=cfg.policy.cuda)
model = resnet18()
policy = ImageClassificationPolicy(cfg.policy, model=model, enable_field=['learn', 'eval'])
learn_dataset = ImageNetDataset(cfg.policy.collect.learn_data_path, is_training=True)
eval_dataset = ImageNetDataset(cfg.policy.collect.eval_data_path, is_training=False)
if cfg.policy.learn.multi_gpu:
learn_sampler = DistributedSampler(learn_dataset)
eval_sampler = DistributedSampler(eval_dataset)
else:
learn_sampler, eval_sampler = None, None
learn_dataloader = DataLoader(learn_dataset, cfg.policy.learn.batch_size, sampler=learn_sampler, num_workers=3)
eval_dataloader = DataLoader(eval_dataset, cfg.policy.eval.batch_size, sampler=eval_sampler, num_workers=2)
# Main components
tb_logger = SummaryWriter(os.path.join('./{}/log/'.format(cfg.exp_name), 'serial'))
learner = BaseLearner(cfg.policy.learn.learner, policy.learn_mode, tb_logger, exp_name=cfg.exp_name)
log_show_hook = ImageClsLogShowHook(
name='image_cls_log_show_hook', priority=0, position='after_iter', freq=cfg.policy.learn.learner.log_show_freq
)
learner.register_hook(log_show_hook)
eval_metric = ImageClassificationMetric()
evaluator = MetricSerialEvaluator(
cfg.policy.eval.evaluator, [eval_dataloader, eval_metric], policy.eval_mode, tb_logger, exp_name=cfg.exp_name
)
# ==========
# Main loop
# ==========
learner.call_hook('before_run')
end = time.time()
for epoch in range(cfg.policy.learn.train_epoch):
# Evaluate policy performance
if evaluator.should_eval(learner.train_iter):
stop, reward = evaluator.eval(learner.save_checkpoint, epoch, 0)
if stop:
break
for i, train_data in enumerate(learn_dataloader):
learner.data_time = time.time() - end
learner.epoch_info = (epoch, i, len(learn_dataloader))
learner.train(train_data)
end = time.time()
learner.policy.get_attribute('lr_scheduler').step()
learner.call_hook('after_run')
if __name__ == "__main__":
main(imagenet_res18_config, 0)
基准算法性能¶
图中为近些年在 Imagenet 数据集中的 Top-K 识别精度对比,
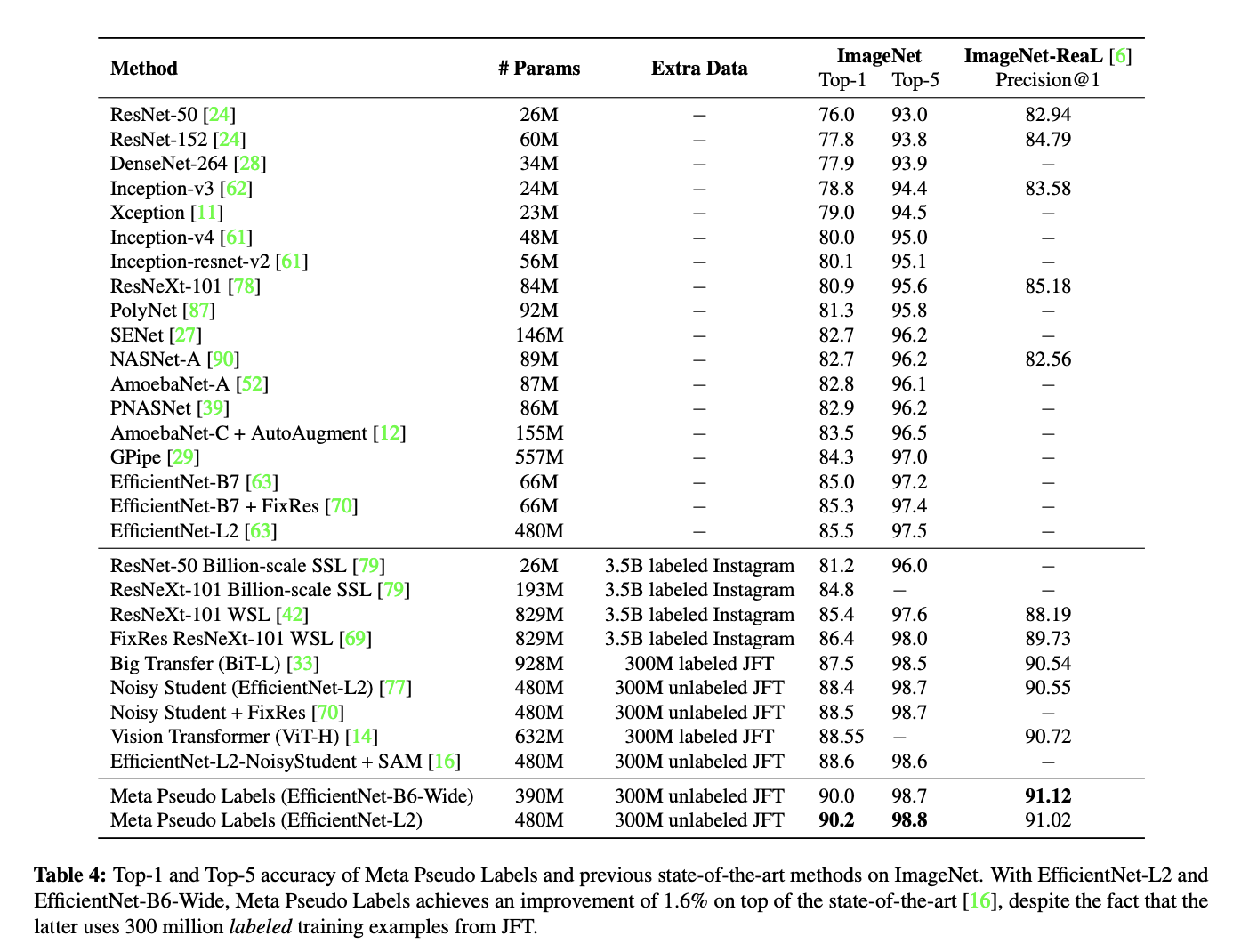
精度对比节选 Meta pseudo labels 中Figure 4。