Slime Volleyball¶
概述¶
Slime Volleyball 是一个双人对战型环境,可以看作一个简化的一对一排球游戏。它是 self-play 相关算法测试的基本环境,其观察空间有向量和图片形式两种,动作空间常简化为离散动作空间。它由三个子环境构成,分别为 SlimeVolley-v0,SlimeVolleyPixel-v0,SlimeVolleyNoFrameskip-v0),下图所示为其中的 SlimeVolley-v0 游戏。
安装¶
安装方法¶
pip 一键安装 slimevolleygym 这个库即可
# Method1: Install Directly
pip install slimevolleygym
验证安装¶
安装完成后,可以通过在 Python 命令行中运行如下命令验证安装成功:
import gym
import slimevolleygym
env = gym.make("SlimeVolley-v0")
obs = env.reset()
print(obs.shape) # (12, )
镜像¶
由于 Slime Volleyball 安装起来非常简单,所以 DI-engine 并没有为其专门准备镜像,可快速通过基准镜像 opendilab/ding:nightly 自定义构建,或访问 docker
hub获取更多镜像
变换前的空间(原始环境)¶
注:这里以 SlimeVolley-v0 为例,因为对 self-play 系列算法做基准测试自然是简单优先。如要用到其他两个环境,可结合原仓库查看,并根据 DI-engine的API 进行相应适配。
观察空间¶
向量观察空间,是一个尺寸为
(12, )的向量,包含了由连续两帧的数据拼接而成的自己,对手,球三者的绝对位置坐标,数据类型为float64即(x_agent, y_agent, x_agent_next, y_agent_next, x_ball, y_ball, x_ball_next, y_ball_next, x_opponent, y_opponent, x_opponent_next, y_opponent_next)
动作空间¶
SlimeVolley-v0的原始动作空间被定义为MultiBinary(3)动作空间,即动作有三种,同一时刻可同时释放多个动作,每个动作对应 0 和 1 两种情况,分别为不执行(0)、执行(1),例如(1, 0, 1)代表同时执行第一种和第三种动作,数据类型为int,需要传入 python list 对象(或是 1 维尺寸为 3 的 np 数组,例如np.array([0, 1, 0])实际环境内部逻辑实现中,并没有严格限制动作必须为 0 和 1,它是将大于 0 值的视作 1,小于等于 0 的值视作 0
在
SlimeVolley-v0环境中,三个动作具体的含义是:0 为索引的动作:向前(forward)
1 为索引的动作:向后(backward)
2 为索引的动作:跳跃(jump)
在 SlimeVolley-v0 环境中,最终组合动作的含义是:
[0, 0, 0], NOOP
[1, 0, 0], LEFT (forward)
[1, 0, 1], UPLEFT (forward jump)
[0, 0, 1], UP (jump)
[0, 1, 1], UPRIGHT (backward jump)
[0, 1, 0], RIGHT (backward)
奖励空间¶
奖励即该游戏得分,如果小球落到己方场地的地面,则奖励 -1,如果落到对方场地的地面,则奖励 +1,如果游戏仍在进行中,则奖励 0
其他¶
游戏结束即为当前环境 episode 结束。游戏结束的条件有两种:
每获得一次 -1 奖励生命值减 1,对战任意一方所有生命值(默认生命值为 5)耗尽,游戏结束;
达到最大环境帧数,3000帧
游戏支持两种对战:智能体对战智能体,智能体对战内置 bot(游戏画面左边是 bot,右边是智能体)
默认的内置 bot 是一个非常简单的 RNN 训练得到的智能体,具体可以参考 bot_link
默认只返回一方的 obs,另外一方的 obs,双方的剩余生命值等信息都在 info 字段中
关键事实¶
(1) 一维向量观察空间(尺寸为 (12, ) ),信息为绝对坐标
(2) MultiBinary 动作空间
(3) 较稀疏奖励(最大生命值为5,最大步数为 3000,只有对战双方扣除生命值时才有奖励)
变换后的空间(RL 环境)¶
观察空间¶
基本无变换,只是简单的格式转换,是一个尺寸为
(12, )的一维np数组,数据类型为np.float32,
动作空间¶
将
MultiBinary动作空间变换为大小为 6 离散动作空间(由简单笛卡尔积并去除其中无意义的动作后得到),最终结果为一维 np 数组,尺寸为(1, ),数据类型为np.int64
奖励空间¶
基本无变换,只是简单的格式转换,一维 np 数组,尺寸为
(1, ),数据类型为np.float32,取值为[-1, 0, 1]
上述空间使用 gym 环境空间定义则可表示为:
import gym
obs_space = gym.spaces.Box(low=-np.inf, high=np.inf, shape=(12, ), dtype=np.float32)
act_space = gym.spaces.Discrete(6)
rew_space = gym.spaces.Box(low=-1, high=1, shape=(1, ), dtype=np.float32)
其他¶
环境
step方法返回的info必须包含eval_episode_return键值对,表示整个 episode 的评测指标,在这里为整个 episode 的奖励累加和(即我方相比对手的生命值差异)如果选择智能体对战内置 bot,请将环境输入配置的
agent_vs_agent字段设置为 False,智能体对战智能体则设置为 True上述空间定义均是对单智能体的说明(即智能体对战内置 bot),多智能体的空间是将上述 obs/action/reward 进行对应拼接等操作,例如观察空间由
(12, )变为(2, 12),代表双方的观察信息
其他¶
惰性初始化¶
为了便于支持环境向量化等并行操作,环境实例一般实现惰性初始化,即__init__方法不初始化真正的原始环境实例,只是设置相关参数和配置值,在第一次调用reset方法时初始化具体的原始环境实例。
随机种子¶
环境中有两部分随机种子需要设置,一是原始环境的随机种子,二是各种环境变换使用到的随机库的随机种子(例如
random,np.random)对于环境调用者,只需通过环境的
seed方法进行设置这两个种子,无需关心具体实现细节环境内部的具体实现:对于原始环境的种子,在调用环境的
reset方法内部,具体的原始环境reset之前设置环境内部的具体实现:对于随机库种子,则在环境的
seed方法中直接设置该值
训练和测试环境的区别¶
训练环境使用动态随机种子,即每个 episode 的随机种子都不同,都是由一个随机数发生器产生,但这个随机数发生器的种子是通过环境的
seed方法固定的;测试环境使用静态随机种子,即每个 episode 的随机种子相同,通过seed方法指定。
存储录像¶
在环境创建之后,重置之前,调用enable_save_replay方法,指定游戏录像保存的路径。环境会在每个 episode 结束之后自动保存本局的录像文件。(默认调用gym.wrappers.RecordVideo实现 ),下面所示的代码将运行一个环境 episode,并将这个 episode 的结果保存在./video/中:
from easydict import EasyDict
from dizoo.slime_volley.envs.slime_volley_env import SlimeVolleyEnv
env = SlimeVolleyEnv(EasyDict({'env_id': 'SlimeVolley-v0', 'agent_vs_agent': False}))
env.enable_save_replay(replay_path='./video')
obs = env.reset()
while True:
action = env.random_action()
timestep = env.step(action)
if timestep.done:
print('Episode is over, eval episode return is: {}'.format(timestep.info['eval_episode_return']))
break
DI-zoo可运行代码示例¶
完整的训练入口文件在 github
link
内,对于具体的入口文件,例如下列所示的slime_volley_selfplay_ppo_main.py,直接使用 python 运行即可:
import os
import gym
import numpy as np
import copy
import torch
from tensorboardX import SummaryWriter
from functools import partial
from ding.config import compile_config
from ding.worker import BaseLearner, BattleSampleSerialCollector, NaiveReplayBuffer, InteractionSerialEvaluator
from ding.envs import SyncSubprocessEnvManager
from ding.policy import PPOPolicy
from ding.model import VAC
from ding.utils import set_pkg_seed
from dizoo.slime_volley.envs import SlimeVolleyEnv
from dizoo.slime_volley.config.slime_volley_ppo_config import main_config
def main(cfg, seed=0, max_iterations=int(1e10)):
cfg = compile_config(
cfg,
SyncSubprocessEnvManager,
PPOPolicy,
BaseLearner,
BattleSampleSerialCollector,
InteractionSerialEvaluator,
NaiveReplayBuffer,
save_cfg=True
)
collector_env_num, evaluator_env_num = cfg.env.collector_env_num, cfg.env.evaluator_env_num
collector_env_cfg = copy.deepcopy(cfg.env)
collector_env_cfg.agent_vs_agent = True
evaluator_env_cfg = copy.deepcopy(cfg.env)
evaluator_env_cfg.agent_vs_agent = False
collector_env = SyncSubprocessEnvManager(
env_fn=[partial(SlimeVolleyEnv, collector_env_cfg) for _ in range(collector_env_num)], cfg=cfg.env.manager
)
evaluator_env = SyncSubprocessEnvManager(
env_fn=[partial(SlimeVolleyEnv, evaluator_env_cfg) for _ in range(evaluator_env_num)], cfg=cfg.env.manager
)
collector_env.seed(seed)
evaluator_env.seed(seed, dynamic_seed=False)
set_pkg_seed(seed, use_cuda=cfg.policy.cuda)
model = VAC(**cfg.policy.model)
policy = PPOPolicy(cfg.policy, model=model)
tb_logger = SummaryWriter(os.path.join('./{}/log/'.format(cfg.exp_name), 'serial'))
learner = BaseLearner(
cfg.policy.learn.learner, policy.learn_mode, tb_logger, exp_name=cfg.exp_name, instance_name='learner1'
)
collector = BattleSampleSerialCollector(
cfg.policy.collect.collector,
collector_env, [policy.collect_mode, policy.collect_mode],
tb_logger,
exp_name=cfg.exp_name
)
evaluator_cfg = copy.deepcopy(cfg.policy.eval.evaluator)
evaluator_cfg.stop_value = cfg.env.stop_value
evaluator = InteractionSerialEvaluator(
evaluator_cfg,
evaluator_env,
policy.eval_mode,
tb_logger,
exp_name=cfg.exp_name,
instance_name='builtin_ai_evaluator'
)
learner.call_hook('before_run')
for _ in range(max_iterations):
if evaluator.should_eval(learner.train_iter):
stop_flag, reward = evaluator.eval(learner.save_checkpoint, learner.train_iter, collector.envstep)
if stop_flag:
break
new_data, _ = collector.collect(train_iter=learner.train_iter)
train_data = new_data[0] + new_data[1]
learner.train(train_data, collector.envstep)
learner.call_hook('after_run')
if __name__ == "__main__":
main(main_config)
注:如要运行智能体对战 bot 的训练程序,直接 python 运行 slime_volley_ppo_config.py 文件即可
注:如要使用其他算法,需调用相应的入口函数
基准算法性能¶
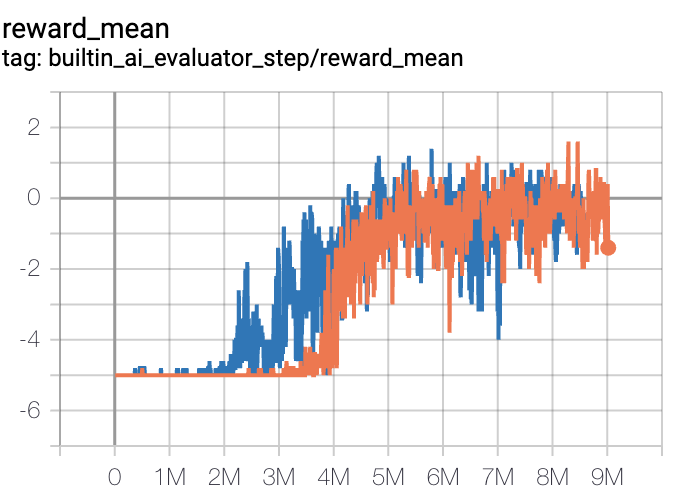
SlimeVolley-v0(平均奖励大于等于 1 视为较好的 Agent,评测指标都是使用智能体对战内置 bot)
SlimeVolley-v0 + PPO + vs Bot
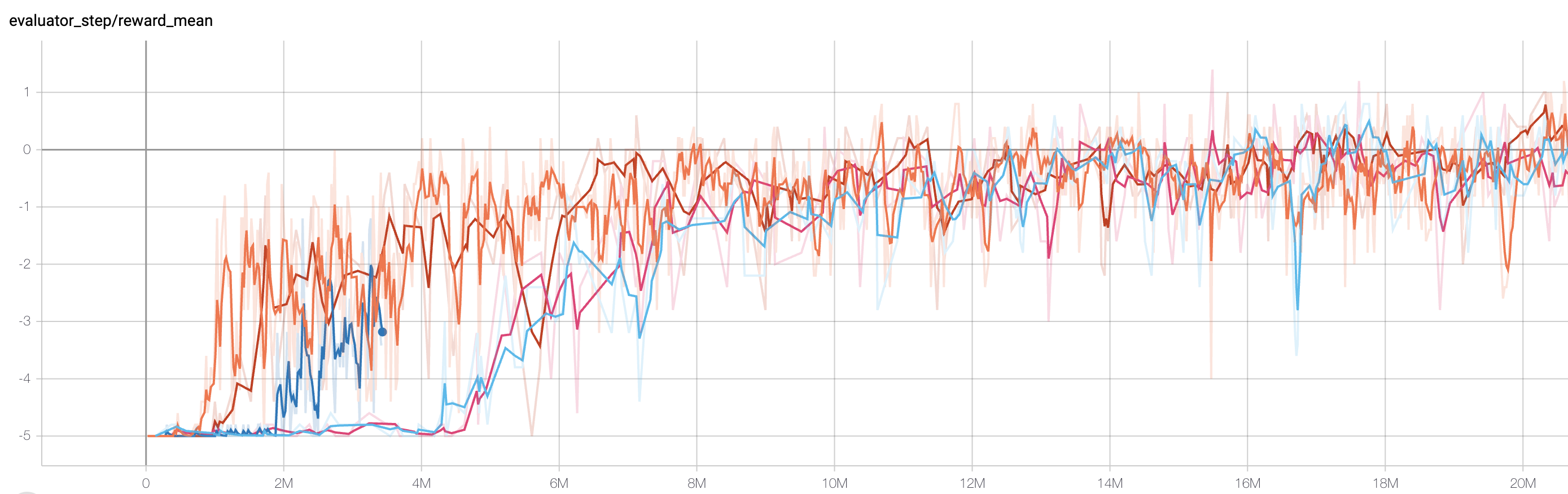
SlimeVolley-v0 + PPO + self-play