SMAC¶
概述¶
SMAC 是一个用于在暴雪星际争霸2上进行多智能体协同强化学习(MARL)的环境。SMAC 用了暴雪星际争霸2 的机器学习 API 和 DeepMind 的PySC2 为智能体与星际争霸2的交互提供了友好的接口,方便开发者观察和执行行动。 与 PySC2 相比,SMAC 专注于分散的微观操作方案,其中游戏的每个智能体均由单独的 RL agent控制。
安装¶
安装方法¶
需要安装星际争霸2 游戏和 PySC2 库,安装方法可以参考DI-star安装
安装主要包括两部分:
1.下载星际争霸2 游戏
对于 Linux 系统使用者,安装路径为https://github.com/Blizzard/s2client-proto#downloads,之后使用 export SC2PATH=<sc2/installation/path> 命令将安装路径添加到环境变量中
对于 Windows 系统使用者,安装请参考https://starcraft2.com
2.安装与 DI-engine 适配的 PySC2
git clone https://github.com/opendilab/DI-star.git
cd DI-star
pip install -e .
验证安装¶
安装完成后,可以通过安装成功后 echo $SC2PATH 确认环境变量设置成功
镜像¶
DI-engine 的镜像配备有框架本身和 Smac 环境,可通过docker pull opendilab/ding:nightly-smac获取,或访问docker
hub获取更多镜像
变换前的空间(原始环境)¶
观察空间¶
可以获取各个智能体是否存活,各个智能体剩余血量,各个智能体视野范围内的盟友或敌人等零碎的信息。
动作空间¶
游戏操作按键空间,一般是大小为 N 的离散动作空间(N随具体子环境变化),数据类型为
int,需要传入 python 数值(或是 0 维 np 数组,例如动作 3 为np.array(3))对于各个地图,动作空间 N 一般等于 6+敌人数,如 3s5z 地图中为 14,2c_vs_64zg 地图中为70。具体的含义是:
0:NOOP
1:STOP
2:MOVE_NORTH
3:MOVE_SOUTH
4:MOVE_EAST
5:MOVE_WEST
6-N: ATTACK ENEMY,所攻击的敌人的 ID 为 N-6
奖励空间¶
游戏胜负,胜利为 1,失败为 0,一般是一个
int数值。
其他¶
游戏结束即为当前环境 episode 结束
关键事实¶
输入为将离散信息综合后的信息
离散动作空间
奖励为稀疏奖励,我们设置 fake_reward,使得训练时所用的奖励为稠密奖励。
变换后的空间(RL 环境)¶
观察空间¶
变换内容:拼接各个 agent 看到的各类离散信息,将拼接后的信息作为各个 agent 看到的 agent_state 和全局的 global_state
变换结果:一个 dict 型数据,其中包含 agent_state,global_state和action_mask,均为一个一维 Tensor 型数组
动作空间¶
基本无变换,依然是大小为N的离散动作空间
奖励空间¶
变换内容:设置 fake_reward,使得智能体在作出一些动作后就可以获得奖励,我们设置每一步的 fake_reward为“打掉的敌人血量-损失的己方血量”,且消灭一个敌人奖励 20 分,获取全局的胜利获得 200 分
变换结果:一个一维且只包含一个 float32 类型数据的 Tensor
其他¶
开启
special_global_state返回的 global_state 则为各个全局信息 + 各个 agent 特殊信息拼接成的信息,若不开启,则仅返回全局信息开启
special_global_state且开启death_mask,则若一个agent阵亡,则其返回的 global_state 仅包含其自身的 ID 信息,其余信息全部被屏蔽环境
step方法返回的info必须包含eval_episode_return键值对,表示整个 episode 的评测指标,在 SMAC 中为整个 episode 的 fake_reward 累加和环境
step方法最终返回的reward为胜利与否
其他¶
惰性初始化¶
为了便于支持环境向量化等并行操作,环境实例一般实现惰性初始化,即__init__方法不初始化真正的原始环境实例,只是设置相关参数和配置值,在第一次调用reset方法时初始化具体的原始环境实例。
随机种子¶
环境中有两部分随机种子需要设置,一是原始环境的随机种子,二是各种环境变换使用到的随机库的随机种子(例如
random,np.random)对于环境调用者,只需通过环境的
seed方法进行设置这两个种子,无需关心具体实现细节环境内部的具体实现:对于原始环境的种子,在调用环境的
reset方法内部,具体的原始环境reset之前设置环境内部的具体实现:对于随机库种子,则在环境的
seed方法中直接设置该值
训练和测试环境的区别¶
训练环境使用动态随机种子,即每个 episode 的随机种子都不同,都是由一个随机数发生器产生,但这个随机数发生器的种子是通过环境的
seed方法固定的;测试环境使用静态随机种子,即每个 episode 的随机种子相同,通过seed方法指定。
存储录像¶
调用https://github.com/opendilab/DI-engine/blob/main/dizoo/smac/utils/eval.py 所提供的方法存储视频,并在星际争霸2游戏中播放存储的视频。
from typing import Union, Optional, List, Any, Callable, Tuple
import pickle
import torch
from functools import partial
from ding.config import compile_config, read_config
from ding.envs import get_vec_env_setting
from ding.policy import create_policy
from ding.utils import set_pkg_seed
def eval(
input_cfg: Union[str, Tuple[dict, dict]],
seed: int = 0,
env_setting: Optional[List[Any]] = None,
model: Optional[torch.nn.Module] = None,
state_dict: Optional[dict] = None,
) -> float:
if isinstance(input_cfg, str):
cfg, create_cfg = read_config(input_cfg)
else:
cfg, create_cfg = input_cfg
create_cfg.policy.type += '_command'
cfg = compile_config(cfg, auto=True, create_cfg=create_cfg)
env_fn, _, evaluator_env_cfg = get_vec_env_setting(cfg.env)
env = env_fn(evaluator_env_cfg[0])
env.seed(seed, dynamic_seed=False)
set_pkg_seed(seed, use_cuda=cfg.policy.cuda)
policy = create_policy(cfg.policy, model=model, enable_field=['eval']).eval_mode
if state_dict is None:
state_dict = torch.load(cfg.learner.load_path, map_location='cpu')
policy.load_state_dict(state_dict)
obs = env.reset()
episode_return = 0.
while True:
policy_output = policy.forward({0: obs})
action = policy_output[0]['action']
print(action)
timestep = env.step(action)
episode_return += timestep.reward
obs = timestep.obs
if timestep.done:
print(timestep.info)
break
env.save_replay(replay_dir='.', prefix=env._map_name)
print('Eval is over! The performance of your RL policy is {}'.format(episode_return))
if __name__ == "__main__":
path = '' #model path
cfg = '' config path
state_dict = torch.load(path, map_location='cpu')
eval(cfg, seed=0, state_dict=state_dict)
DI-zoo可运行代码示例¶
完整的训练配置文件在 github
link
内,对于具体的配置文件,例如smac_3s5z_mappo_config.py,使用如下的 demo 即可运行:
import sys
from copy import deepcopy
from ding.entry import serial_pipeline_onpolicy
from easydict import EasyDict
agent_num = 8
collector_env_num = 8
evaluator_env_num = 8
special_global_state = True
main_config = dict(
exp_name='smac_3s5z_mappo',
env=dict(
map_name='3s5z',
difficulty=7,
reward_only_positive=True,
mirror_opponent=False,
agent_num=agent_num,
collector_env_num=collector_env_num,
evaluator_env_num=evaluator_env_num,
n_evaluator_episode=16,
stop_value=0.99,
death_mask=False,
special_global_state=special_global_state,
# save_replay_episodes = 1,
manager=dict(
shared_memory=False,
reset_timeout=6000,
),
),
policy=dict(
cuda=True,
multi_agent=True,
continuous=False,
model=dict(
# (int) agent_num: The number of the agent.
# For SMAC 3s5z, agent_num=8; for 2c_vs_64zg, agent_num=2.
agent_num=agent_num,
# (int) obs_shape: The shapeension of observation of each agent.
# For 3s5z, obs_shape=150; for 2c_vs_64zg, agent_num=404.
# (int) global_obs_shape: The shapeension of global observation.
# For 3s5z, obs_shape=216; for 2c_vs_64zg, agent_num=342.
agent_obs_shape=150,
#global_obs_shape=216,
global_obs_shape=295,
# (int) action_shape: The number of action which each agent can take.
# action_shape= the number of common action (6) + the number of enemies.
# For 3s5z, obs_shape=14 (6+8); for 2c_vs_64zg, agent_num=70 (6+64).
action_shape=14,
# (List[int]) The size of hidden layer
# hidden_size_list=[64],
),
# used in state_num of hidden_state
learn=dict(
# (bool) Whether to use multi gpu
multi_gpu=False,
epoch_per_collect=5,
batch_size=3200,
learning_rate=5e-4,
# ==============================================================
# The following configs is algorithm-specific
# ==============================================================
# (float) The loss weight of value network, policy network weight is set to 1
value_weight=0.5,
# (float) The loss weight of entropy regularization, policy network weight is set to 1
entropy_weight=0.01,
# (float) PPO clip ratio, defaults to 0.2
clip_ratio=0.2,
# (bool) Whether to use advantage norm in a whole training batch
adv_norm=False,
value_norm=True,
ppo_param_init=True,
grad_clip_type='clip_norm',
grad_clip_value=10,
ignore_done=False,
),
on_policy=True,
collect=dict(env_num=collector_env_num, n_sample=3200),
eval=dict(env_num=evaluator_env_num, evaluator=dict(eval_freq=50, )),
),
)
main_config = EasyDict(main_config)
create_config = dict(
env=dict(
type='smac',
import_names=['dizoo.smac.envs.smac_env'],
),
env_manager=dict(type='base'),
policy=dict(type='ppo'),
)
create_config = EasyDict(create_config)
if __name__ == "__main__":
serial_pipeline_onpolicy([main_config, create_config], seed=0)
注:对于 on-policy 算法,使用 serial_pipeline_onpolicy 进入,对于 off-policy 算法,使用 serial_pipeline 进入
基准算法性能¶
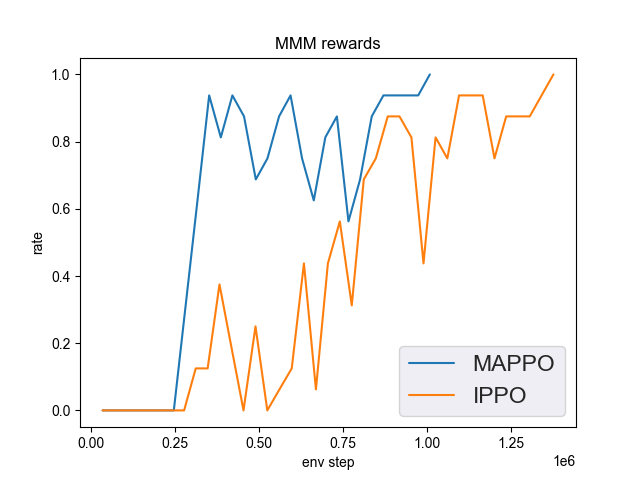
MMM(2M env step 下胜率为 1 视为较好性能)
MMM + MAPPO
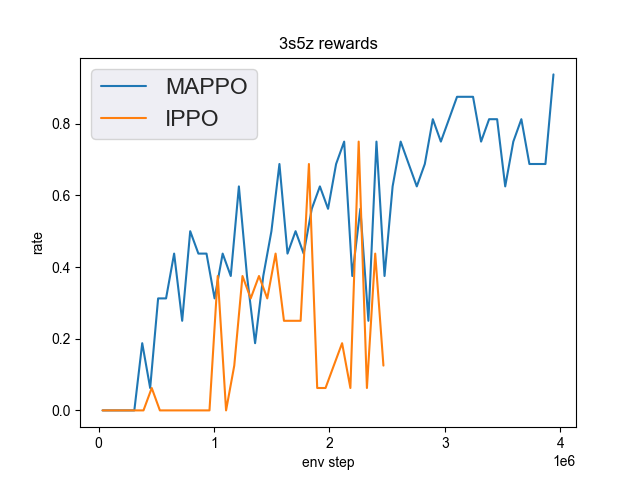
3s5z(3M env step 下胜率为 1 视为较好性能)
3s5z + MAPPO
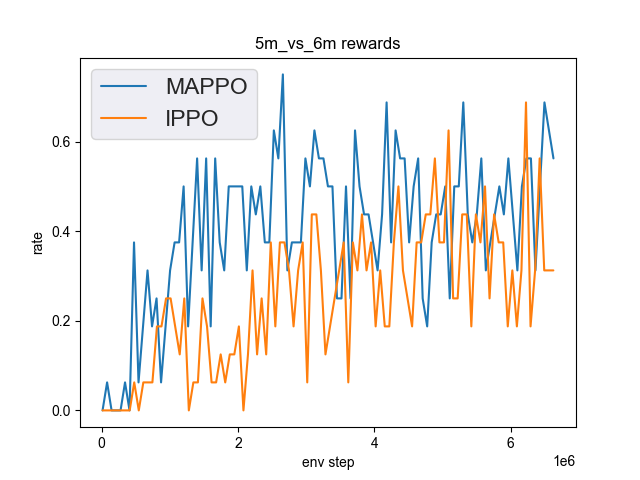
5m_vs_6m(5M env step 下胜率为 0.75 视为较好性能)
5m_vs_6m + MAPPO
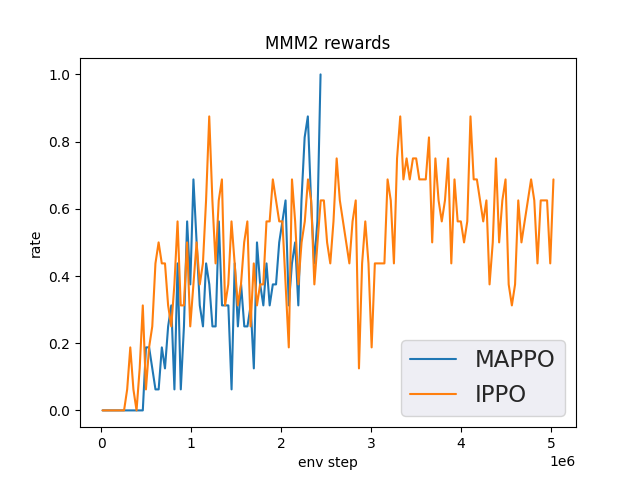
MMM2(5M env step 下胜率为 1 视为较好性能)
MMM2 + MAPPO