CartPole¶
Overview¶
The inverted pendulum problem is a classic control problem in reinforcement learning. CartPole is a discrete control task in the inverted pendulum problem. In the game there is a car with a pole on it. The cart slides side to side on a smooth and frictionless track to keep the pole upright. As shown below.

Install¶
Installation Method¶
The CartPole environment is built into the gym, and you can install the gym directly. Its environment id is CartPole-v0.
pip install gym
Verify Installation¶
Run the following command on the Python command line to verify that the installation is successful.
import gym
env = gym.make('CartPole-v0')
obs = env.reset()
print(obs)
Environment Introduction¶
Action Space¶
The action space of CartPole belongs to the discrete action space, and there are two discrete actions, namely left shift and right shift.
Left Move: 0 means to move the agent to the left.Right move: 1 means to move the agent to the right.
Using the gym environment space definition can be expressed as:
action_space = spaces.Discrete(2)
State Space¶
CartPole’s state space has 4 elements, which are:
Cart Position: Cart position, in the range[-4.8, 4.8].Cart Velocity: The speed of the cart, in the range[-inf, inf].Pole Angle: The angle of the pole, in the range[-24 deg, 24 deg].Pole Angular Velocity: The angular velocity of the pole, in the range[-inf, inf].
Reward Space¶
Each step will receive a reward of 1 until the episode terminates (the termination state will also receive a reward of 1).
Termination Condition¶
The termination condition for each episode of the CartPole environment is any of the following:
The angle of the rod offset is more than 12 degrees.
The cart is out of bounds, and the distance is usually set as 2.4.
Reaching the maximum step of episode, whose default is 200.
When Does the CartPole Mission Count as a Victory¶
When the average episode reward for 100 trials reaches 195 or more, the game is considered a victory.
Others¶
Store Video¶
Some environments have their own rendering plug-ins, but DI-engine does not support the rendering plug-ins that come with the environment, but generates video recordings by saving the logs during training. For details, please refer to the Visualization & Logging section under the DI-engine official documentation Quick start chapter.
DI-zoo Runnable Code Example¶
The following provides a complete CartPole environment config, using the DQN algorithm as the policy. Please run the dqn_nstep.py file in the DI-engine/ding/example directory, as follows.
import gym
from ditk import logging
from ding.model import DQN
from ding.policy import DQNPolicy
from ding.envs import DingEnvWrapper, BaseEnvManagerV2
from ding.data import DequeBuffer
from ding.config import compile_config
from ding.framework import task
from ding.framework.context import OnlineRLContext
from ding.framework.middleware import OffPolicyLearner, StepCollector, interaction_evaluator, data_pusher, \
eps_greedy_handler, CkptSaver, nstep_reward_enhancer, final_ctx_saver
from ding.utils import set_pkg_seed
from dizoo.classic_control.cartpole.config.cartpole_dqn_config import main_config, create_config
def main():
logging.getLogger().setLevel(logging.INFO)
main_config.exp_name = 'cartpole_dqn_nstep'
main_config.policy.nstep = 3
cfg = compile_config(main_config, create_cfg=create_config, auto=True)
with task.start(async_mode=False, ctx=OnlineRLContext()):
collector_env = BaseEnvManagerV2(
env_fn=[lambda: DingEnvWrapper(gym.make("CartPole-v0")) for _ in range(cfg.env.collector_env_num)],
cfg=cfg.env.manager
)
evaluator_env = BaseEnvManagerV2(
env_fn=[lambda: DingEnvWrapper(gym.make("CartPole-v0")) for _ in range(cfg.env.evaluator_env_num)],
cfg=cfg.env.manager
)
set_pkg_seed(cfg.seed, use_cuda=cfg.policy.cuda)
model = DQN(**cfg.policy.model)
buffer_ = DequeBuffer(size=cfg.policy.other.replay_buffer.replay_buffer_size)
policy = DQNPolicy(cfg.policy, model=model)
task.use(interaction_evaluator(cfg, policy.eval_mode, evaluator_env))
task.use(eps_greedy_handler(cfg))
task.use(StepCollector(cfg, policy.collect_mode, collector_env))
task.use(nstep_reward_enhancer(cfg))
task.use(data_pusher(cfg, buffer_))
task.use(OffPolicyLearner(cfg, policy.learn_mode, buffer_))
task.use(CkptSaver(policy, cfg.exp_name, train_freq=100))
task.use(final_ctx_saver(cfg.exp_name))
task.run()
if __name__ == "__main__":
main()
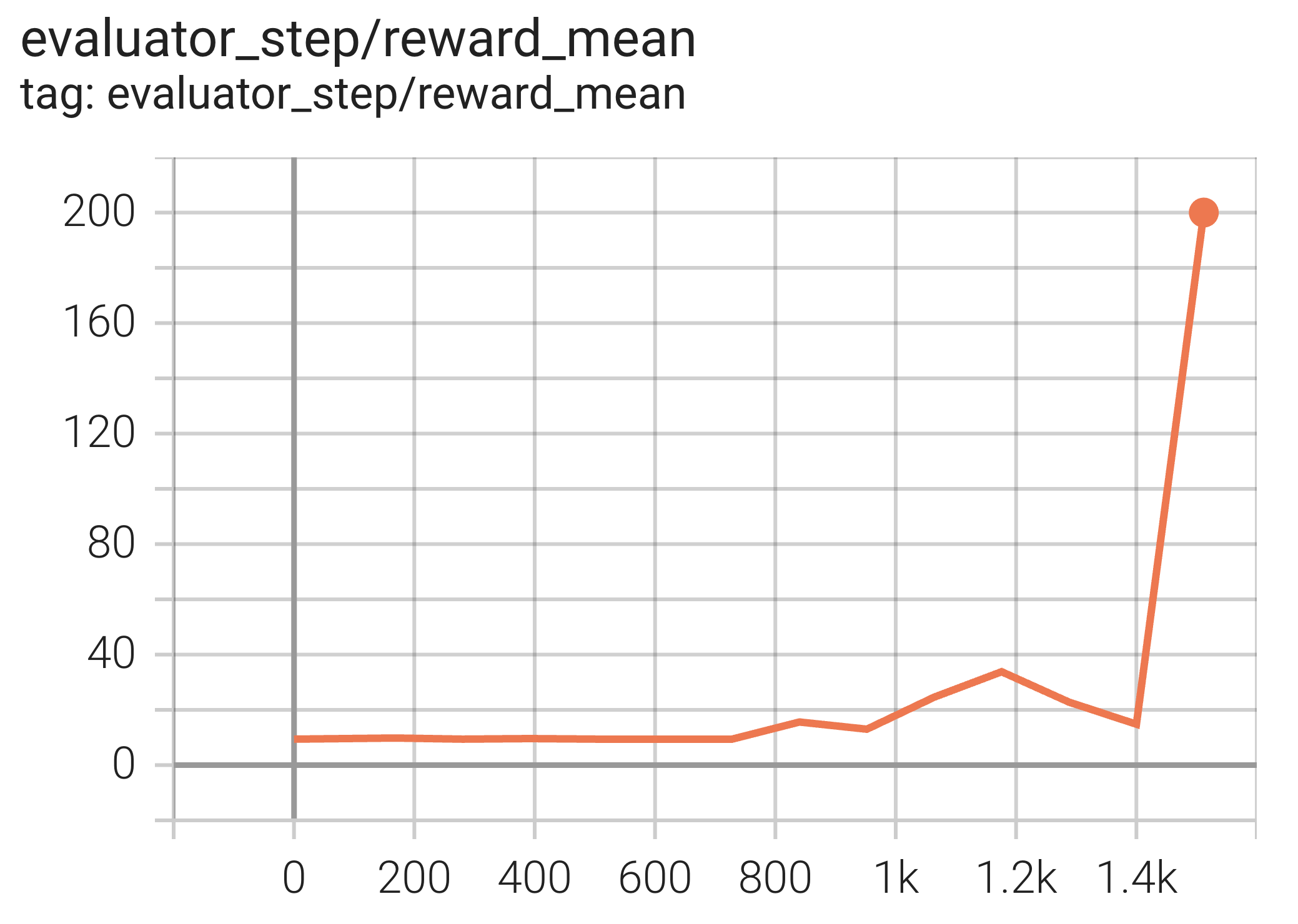
Experimental Results¶
The experimental results using the DQN algorithm are as follows. The abscissa is env step , and the ordinate is episode reward (return) mean .
References¶
CartPole source code