MuJoCo¶
Overview¶
Mujoco is a physics engine designed to facilitate research and development in areas such as robotics, biomechanics, graphics, and animation that require fast and accurate simulation. It is often used as a benchmarking environment for continuous-space reinforcement learning algorithms. It is a collection of a series of environments (a total of 20 sub-environments), commonly used sub-environments are Ant, Half Cheetah, Hopper, Huanmoid , Walker2D, etc. The following figure shows the Hopper game.

Install¶
Installation Method¶
First, install a MuJoCo library of a specific version in your operation system. Then, install three Python libraries, gym, mujoco and mujoco-py , which can be installed by one-click pip or combined with DI-engine.
pip install DI-engine[common_env,video]
Note:
The mujoco library is open-source and free to public, and thus no longer requires an activation license. You can use Deepmind’s latest mujoco library, or use OpenAI’s mujoco-py.
If you install
mujoco-py>=2.1.0, you can do the following:
# Installation for Linux
# Download the MuJoCo version 2.1 binaries for Linux.
wget https://mujoco.org/download/mujoco210-linux-x86_64.tar.gz
# Extract the downloaded mujoco210 directory into ~/.mujoco/mujoco210.
tar xvf mujoco210-linux-x86_64.tar.gz && mkdir -p ~/.mujoco && mv mujoco210 ~/.mujoco/mujoco210
# Add path
echo "export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:~/.mujoco/mjpro210/bin:~/.mujoco/mujoco210/bin" >> ~/.bashrc
source ~/.bashrc
# Install and use mujoco-py
pip install gym
pip install -U 'mujoco-py<2.2,>=2.1'
# Installation for macOS
# Download the MuJoCo version 2.1 binaries for OSX.
wget https://mujoco.org/download/mujoco210-macos-x86_64.tar.gz
# Extract the downloaded mujoco210 directory into ~/.mujoco/mujoco210.
tar xvf mujoco210-macos-x86_64.tar.gz && mkdir -p ~/.mujoco && mv mujoco210 ~/.mujoco/mujoco210
# Add path
echo "export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:~/.mujoco/mjpro210/bin:~/.mujoco/mujoco210/bin" >> ~/.bashrc
source ~/.bashrc
# Install and use mujoco-py
pip install gym
pip install -U 'mujoco-py<2.2,>=2.1'
If you install
mujoco-py<2.1.0, you can do the following:
# Installation for Linux
# Download the MuJoCo version 2.0 binaries for Linux.
wget https://www.roboti.us/download/mujoco200_linux.zip
# Extract the downloaded mujoco200 directory into ~/.mujoco/mujoco200.
unzip mujoco200_linux.zip && mkdir -p ~/.mujoco && mv mujoco200_linux ~/.mujoco/mujoco200
# Download unlocked activation key.
wget https://www.roboti.us/file/mjkey.txt -O ~/.mujoco/mjkey.txt
# Install and use mujoco-py
pip install gym
pip install -U 'mujoco-py<2.1'
# Installation for macOS
# Download the MuJoCo version 2.0 binaries for OSX.
wget https://www.roboti.us/download/mujoco200_macos.zip
# Extract the downloaded mujoco200 directory into ~/.mujoco/mujoco200.
tar xvf mujoco200-macos-x86_64.tar.gz && mkdir -p ~/.mujoco && mv mujoco200_macos ~/.mujoco/mujoco200
# Download unlocked activation key.
wget https://www.roboti.us/file/mjkey.txt -O ~/.mujoco/mjkey.txt
# Install and use mujoco-py
pip install gym
pip install -U 'mujoco-py<2.1'
If you install
mujoco>=2.2.0, you can do the following:
# Install the MuJoCo version >=2.2.0
pip install mujoco
pip install gym
Verify Installation¶
After the installation is complete, you can verify that the installation was successful by running the following command on the Python command line:
import gym
env = gym.make('Hopper-v3')
obs = env.reset()
print(obs.shape) # (11, )
Image¶
The image of the DI-engine comes with the framework itself and the Mujoco environment, available via docker pull opendilab/ding:nightly-mujoco, or by accessing docker
hub Get more images
Space Before Transformation (Original Environment)¶
Observation Space¶
A vector composed of physical information (3D position, orientation, and joint angles etc. ), the specific size is
(N, ), whereNis determined according to the environment, and the data type isfloat64
Action Space¶
A vector (torque etc.) composed of physical information, generally a continuous action space of size N (N varies with the specific sub-environment), the data type is
np.float32, and an np array needs to be passed in (for example, The action isarray([-0.9266078 , -0.4958926 , 0.46242517], dtype =np.float32))For example, in the Hopper environment, the size of N is 3, and the action takes the value in
[-1, 1]
Reward Space¶
The game score will vary greatly depending on the specific game content. Generally, it is a
floatvalue. For the specific value, please refer to the benchmark algorithm performance section at the bottom.
Other¶
The end of the game is the end of the current environment episode
Key Facts¶
Vector physical information input, according to actual experience, it is not appropriate to subtract the mean value when doing norm.
Continuous action space
Dense rewards
The scale of reward value varies greatly
Transformed Space (RL Environment)¶
Observation Space¶
Basically no transformation
Action Space¶
Basically no transformation, it is still a continuous action space of size N, the value range is
[-1, 1], the size is(N, ), and the data type isnp.float32
Reward Space¶
Basically no transformation
The above space can be expressed as:
import gym
obs_space = gym.spaces.Box(low=-np.inf, high=np.inf, shape=(11, ), dtype=np.float64)
act_space = gym.spaces.Box(low=-1, high=1, shape=(3, ), dtype=np.float32)
rew_space = gym.spaces.Box(low=-np.inf, high=np.inf, shape=(1, ), dtype=np.float32)
Other¶
The
inforeturned by the environmentstepmethod must containeval_episode_returnkey-value pair, indicating the evaluation index of the entire episode, and the cumulative sum of the rewards of the entire episode in Mujoco
Other¶
Lazy Initialization¶
In order to facilitate parallel operations such as environment vectorization, environment instances generally implement lazy initialization, that is, the __init__method does not initialize the real original environment instance, but only sets relevant parameters and configuration values. Theresetmethod initializes the concrete original environment instance.
Random Seed¶
There are two parts of the random seed that need to be set in the environment, one is the random seed of the original environment, and the other is the random seed of the random library used by various environment transformations (such as
random,np.random)For the environment caller, just set these two seeds through the
seedmethod of the environment, and do not need to care about the specific implementation detailsConcrete implementation inside the environment: For the seed of the original environment, set before calling the
resetmethod of the environment, before the concreteresetConcrete implementation inside the environment: For random library seeds, set the value directly in the
seedmethod of the environment
The Difference between Training and Testing Environments¶
The training environment uses a dynamic random seed, that is, the random seed of each episode is different, and is generated by a random number generator, but the seed of this random number generator is fixed by the
seedmethod of the environment ;The test environment uses a static random seed, that is, the random seed of each episode is the same, specified by theseedmethod.
Store Video¶
After the environment is created, but before reset, call theenable_save_replaymethod to specify the path to save the game replay. The environment will automatically save the local video files after each episode ends. (The default call gym.wrappers.RecordVideoimplementation), the code shown below will run an environment episode, and save the result of this episode in a folder ./video/:
from easydict import EasyDict
from dizoo.mujoco.envs import MujocoEnv
config = MujocoEnv.default_config()
config.env_id="Hopper-v3"
env = MujocoEnv(config)
env.enable_save_replay(replay_path='./video')
obs = env.reset()
while True:
action = env.random_action()
timestep = env.step(action)
if timestep.done:
print('Episode is over, eval episode return is: {}'.format(timestep.info['eval_episode_return']))
break
DI-zoo Runnable Code Example¶
The full training configuration file is at github
link
Inside, for specific configuration files, such ashopper_sac_default_config.py, use the following demo to run:
from easydict import EasyDict
hopper_sac_default_config = dict(
env=dict(
env_id='Hopper-v3',
norm_obs=dict(use_norm=False, ),
norm_reward=dict(use_norm=False, ),
collector_env_num=1,
evaluator_env_num=8,
use_act_scale=True,
n_evaluator_episode=8,
stop_value=6000,
),
policy=dict(
cuda=True,
on_policy=False,
random_collect_size=10000,
model=dict(
obs_shape=11,
action_shape=3,
twin_critic=True,
actor_head_type='reparameterization',
actor_head_hidden_size=256,
critic_head_hidden_size=256,
),
learn=dict(
update_per_collect=1,
batch_size=256,
learning_rate_q=1e-3,
learning_rate_policy=1e-3,
learning_rate_alpha=3e-4,
ignore_done=False,
target_theta=0.005,
discount_factor=0.99,
alpha=0.2,
reparameterization=True,
auto_alpha=False,
),
collect=dict(
n_sample=1,
unroll_len=1,
),
command=dict(),
eval=dict(),
other=dict(replay_buffer=dict(replay_buffer_size=1000000, ), ),
),
)
hopper_sac_default_config = EasyDict(hopper_sac_default_config)
main_config = hopper_sac_default_config
hopper_sac_default_create_config = dict(
env=dict(
type='mujoco',
import_names=['dizoo.mujoco.envs.mujoco_env'],
),
env_manager=dict(type='base'),
policy=dict(
type='sac',
import_names=['ding.policy.sac'],
),
replay_buffer=dict(type='naive', ),
)
hopper_sac_default_create_config = EasyDict(hopper_sac_default_create_config)
create_config = hopper_sac_default_create_config
if __name__ == '__main__':
from ding.entry import serial_pipeline
serial_pipeline((main_config, create_config), seed=0)
Note: For some special algorithms, such as PPO, special entry functions need to be used. For examples, please refer to
link
You can also use serial_pipeline_onpolicy to enter with one click.
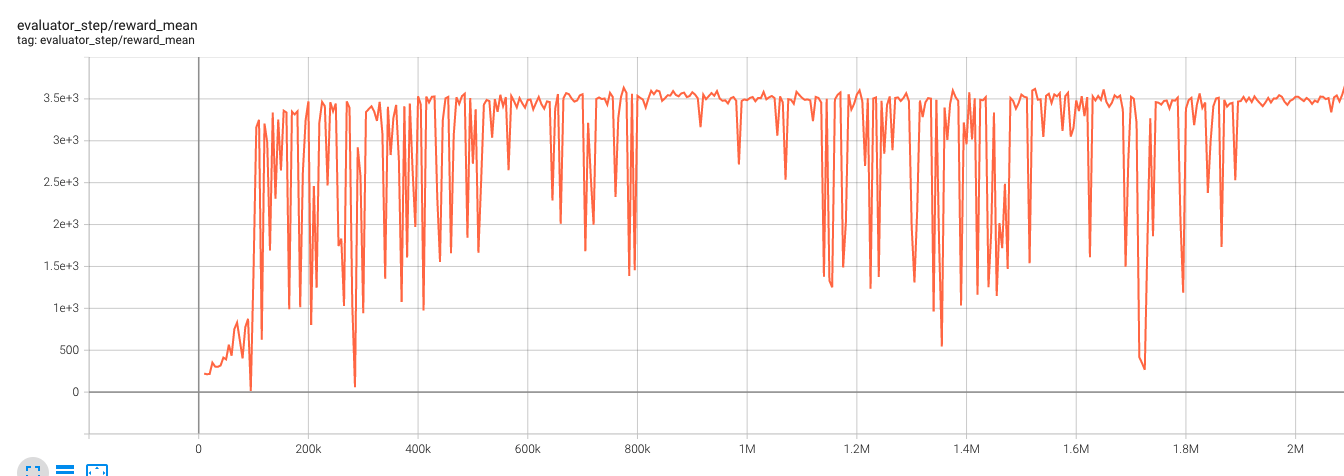
Benchmark Algorithm Performance¶
Hopper-v3
Hopper-v3 + SAC