How to construct a data pipeline for Imitation Learning / Offline Training¶
Overview¶
Generally speaking, data pipeline for Imitation Learning or Offline Training mainly contains three steps:
Train an expert policy.
Generate data. In this step, the previous expert is used to generate demonstration data.
Imitation Learning / Offline Training. Finally, given generated expert data, we can conduct corresponding Imitation Learning or Offline Training.
For better illustrating this pipeline, we take two examples: Behavioral Cloning (BC) and Extrapolating Beyond Suboptimal Demonstrations via Inverse Reinforcement Learning from Observations (TREX) . The pipline of these two algorithms are shown as below.
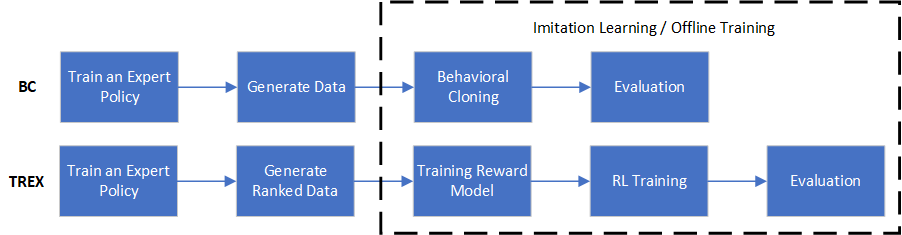
Next, we will introduce details about how to implement the pipeline of these two algorithms.
Train an expert policy¶
In this step, we will train an expert policy, which has no difference with standard RL process. For example, to perform PPO on cartpole, we can use:
from copy import deepcopy from easydict import EasyDict from dizoo.classic_control.cartpole.config.cartpole_ppo_offpolicy_config import cartpole_ppo_offpolicy_config,\ cartpole_ppo_offpolicy_create_config from ding.entry import serial_pipeline_bc, collect_demo_data, serial_pipeline config = [deepcopy(cartpole_ppo_offpolicy_config), deepcopy(cartpole_ppo_offpolicy_create_config)] config[0].policy.learn.learner.hook.save_ckpt_after_iter = 100 expert_policy = serial_pipeline(config, seed=0)
Generate data¶
In this step, the expert policy will generate demonstration data.
For different Imitation Learning or Offline Training algorithms, formats of demonstration data may be different. If we only require state-action pair (e.g. BC), the demonstration data can be easily generated like:
collect_count = 10000 # number of transitions to collect expert_data_path = 'expert_data_ppo_bc.pkl' # data path to be saved state_dict = expert_policy.collect_mode.state_dict() collect_config = [deepcopy(cartpole_ppo_offpolicy_config), deepcopy(cartpole_ppo_offpolicy_create_config)] collect_config[0].exp_name = 'test_serial_pipeline_bc_ppo_collect' collect_demo_data( collect_config, seed=0, state_dict=state_dict, expert_data_path=expert_data_path, collect_count=collect_count )
Because the collect config is almost the same compared to the expert config, we directly modify the original config.
For TREX, however, data generation process is more complicated and is shown as below:
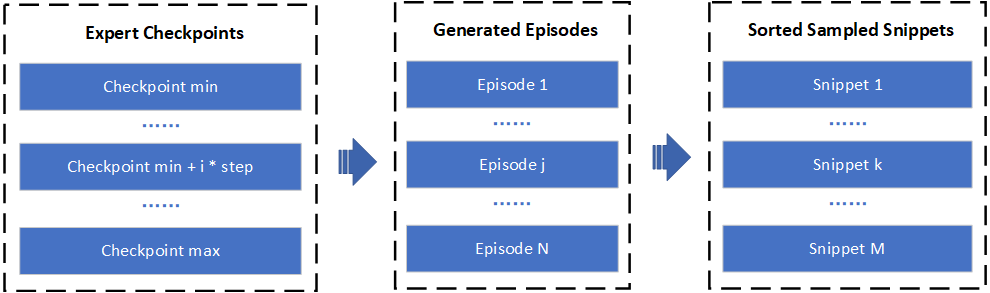
Firstly, we load different expert models to generate various demonstration episodes. Then, the episodes will be sampled into snippets with shorter sequence length, which are sorted according to their total return.
In our implementation, the process above is included in one function. The method for collecting TREX data is:
from ding.entry.application_entry_trex_collect_data import trex_collecting_data from dizoo.classic_control.cartpole.config.cartpole_trex_offppo_config import cartpole_trex_offppo_config,\ cartpole_trex_offppo_create_config exp_name = 'test_serial_pipeline_trex_collect' collect_config = [deepcopy(cartpole_trex_offppo_config), deepcopy(cartpole_trex_offppo_create_config)] collect_config[0].exp_name = exp_name collect_config[0].reward_model.data_path = exp_name collect_config[0].reward_model.reward_model_path = exp_name + '/cartpole.params' # path for saving TREX reward model collect_config[0].reward_model.expert_model_path = config[0].exp_name args = EasyDict({'cfg': deepcopy(collect_config), 'seed': 0, 'device': 'cpu'}) trex_collecting_data(args=args)
Imitation Learning / Offline Training¶
Finally in this step, we will use the generated demonstration data for Imitation Learning / Offline Training. For BC, we can use:
from dizoo.classic_control.cartpole.config.cartpole_bc_config import cartpole_bc_config,\ cartpole_bc_create_config il_config = [deepcopy(cartpole_bc_config), deepcopy(cartpole_bc_create_config)] _, converge_stop_flag = serial_pipeline_bc(il_config, seed=0, data_path=expert_data_path) assert converge_stop_flag
For TREX, we can use:
from ding.entry import serial_pipeline_preference_based_irl serial_pipeline_preference_based_irl(collect_config, seed=0, max_train_iter=1)
Notably, we integrate all the algorithm-specific code into each serial_pipeline.
For BC, this process contains cloning the expert behavior and evaluation for the result. For TREX, a reward model is trained to predict the reward of an observation. Then RL algorithms are applied to maximize the predicted reward and is finally evaluated. The key in this process is to replace the real reward with predicted reward:
def estimate(self, data: list) -> List[Dict]: """ Overview: Estimate reward by rewriting the reward key in each row of the data. Arguments: - data (:obj:`list`): the list of data used for estimation, with at least \ ``obs`` and ``action`` keys. Effects: - This is a side effect function which updates the reward values in place. """ train_data_augmented = self.reward_deepcopy(data) res = collect_states(train_data_augmented) res = torch.stack(res).to(self.device) with torch.no_grad(): sum_rewards, sum_abs_rewards = self.reward_model.cum_return(res, mode='batch') for item, rew in zip(train_data_augmented, sum_rewards): item['reward'] = rew return train_data_augmented