Multi-Agent Reinforcement Learning¶
Problem Definition and Research Motivation¶
In many real-world scenarios, people need to control multiple agents that exist at the same time to complete specific tasks, such as traffic control, robot collaboration, autonomous driving, and multiplayer online games. Therefore, the research on reinforcement learning has gradually extended from the field of single agent to multi-agent reinforcement learning (MARL). In recent years, deep reinforcement learning has shown great potential in multi-agent environments and games, such as the sub-environment SMAC of StarCraft II [7] , the football game Gfootball , and autonomous driving environments such as Carla .
In MARL, the policy controls multiple agents to interact with the environment simultaneously, and the goal is still to maximize the cumulative reward. In this case, the state transition function and the reward function of the environment are conditioned on the joint action of all agents rather than the single action of one agent. Therefore, in the process of policy learning, the update of each agent’s policy needs to consider the current policies of other agents.
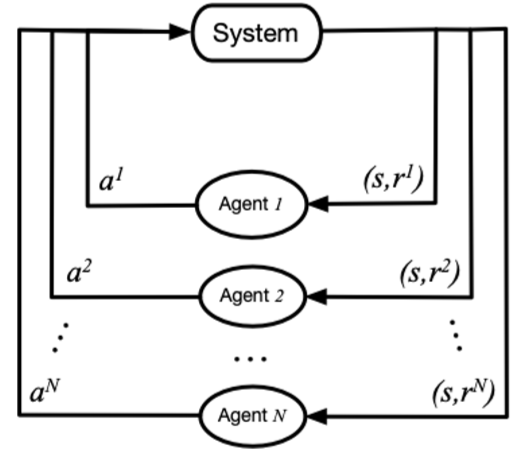
In this figure 1, \(system\) represents a multi-agent environment, \(Agent_i\) represents the ith agent, \(a_i\) represents the action taken by the ith agent, \(r_i\) represents the local reward obtained by the ith agent. During the training process, each agent interacts with the environment separately, and the system feeds back a joint reward.
In general, the main difference between multi-agent reinforcement learning and single-agent reinforcement learning lies in the following four points:
The non-stationary of the environment: While the agent is making a decision, other agents are also taking actions, and the change of the environment state is related to the joint action of all the agents. Therefore, the value evaluation of the actions of a single agent will change with the actions of other agents, which will lead to non-stationary in MARL training.
Limitations of information acquisition by agents: In some environments (such as SMAC), each agent may not be able to obtain global state information, but only local observation information. However, it is impossible to know the observation information, actions and other information of other agents.
Individual goal consistency: The goal of each agent may be the optimal global return or the optimal local return.
Scalability: Large-scale multi-agent systems may involve high-dimensional state space and action space, which poses certain challenges for model expression ability, algorithm learning ability and hardware computing power in real scenarios.
Research Direction¶
For MARL cooperation tasks, the simplest idea is to directly apply single-agent reinforcement learning methods to multi-agent systems. Specifically, each agent regards other agents as part of the environment, and then utilize the single agent reinforcement learning paradigms. This is the basic idea of independent Q-learning, independent PPO, but due to the non-stationarity of the environment and the locality of agent observation, these methods are difficult to achieve good results.
At present, the cooperative tasks in MARL mainly adopt the CTDE paradigm (centralized training and decentralized execution), which mainly include two types of learning methods, Valued-based MARL and Actor-Critic MARL. Please refer to Figure 2 for details:
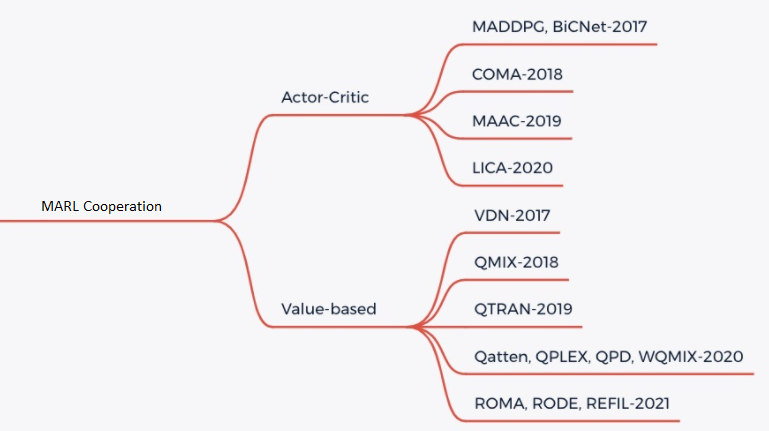
Valued-based MARL
For Valued-based MARL, the main idea is the factorization [3] of the joint action-value function \(Q_tot\) into individual ones \(Q_a\) for decentralized execution. In order to achieve CTDE, we need to ensure that factorization satisfy the IGM assumption: the a global argmax performed on \(Q_tot\) yields the same result as a set of individual argmax operations performed on each \(Q_a\). There are mainly QMIX, WQMIX, QTRAN and other methods:
QMIX: The core of QMIX is to learn a monotonic Q-value mixed network, and the Q-value of each agent is summed by nonlinear transformation to generate \(Q_tot\). For details, please refer to QMIX [2]
WQMIX: The core of WQMIX is the same as that of QMIX, and it also learns a Q-value mixed network, but it learns a Q-value mixed network that can break through the monotonicity limit through the weighted projection method. For details, please refer to WQMIX [1]
QTRAN: QTRAN breaks through the monotonicity limitation by learning independent action-value networks, hybrid action-value networks, and global state-value networks. For details, please refer to QTRAN [4]
QPLEX: QPLEX decomposes the joint Q-value \(Q_tot\) and the Q-value of each agent \(Q_i\) using a Dueling structure, respectively. The IGM consistency is transformed into an easy-to-implement advantage function value range constraint, which facilitates the learning of value functions with a linear decomposition structure. For details, please refer to QPLEX [8]
Actor-Critic MARL
For Actor-Critic MARL, the main idea is to use the policy gradient theorem to update the policy networks while learning a fully centralized state-action value function and use it to guide the optimization of decentralized policies.
COMA: COMA uses counterfactual baselines to address the challenge of credit assignment across multiple agents and a critic network to efficiently compute counterfactual baselines. For details, please refer to COMA [5]
MAPPO: The basic idea of MAPPO is the same as that of PPO, but the input to the Actor network is the Local observation of each agent, and the input to the Critic network is the Agent specific global state of each agent. For details, please refer to MAPPO [6]
Future Study¶
For some environments with more agents and more complex environments, such as some sub-environments of Multi-Agent Petting Zoo, there are nearly a hundred agents, and pure MARL cooperation may not be able to achieve good results, which requires real-time communication between agents to share information.
For some practical situations, such as automatic driving, the bandwidth pressure required to obtain the real-time global state is too large, especially when the number of vehicles is large, it is almost impossible to obtain the real-time global state, and the CTDE method cannot be used for training.
In the above cases 1 and 2, the method of MARL Communication between multiple agents can be used to further improve the learning efficiency.
In the future, MARL can be combined with Offline RL techniques to further improve sample efficiency. At the same time, MARL can also be applied to many fields such as agent behavior analysis, agent modeling, human-machine collaboration and so on.